第七讲:为什么模板不是随手截个图?这套系统真正难的是模板生产链
Why Templates Are Not Just Cropped Images: The Real Difficulty Lies in the Template Production Chain
English Abstract
This article explains why template creation in the inspection system is not a trivial image-cropping step, but a full production chain. Templates must be validated, corrected, standardized, and organized into structural objects before they can enter XML, CSV, and the downstream detection pipeline. More importantly, template production also determines the minimal registration unit: some templates are built from a single character, while others deliberately merge multiple characters or local structures to improve the robustness of nonrigid registration. From this perspective, template production is not a preparatory convenience, but an upstream structural mechanism that directly affects registration stability, missed defects, and false alarms.
在前面几篇里,我已经讲了这套系统的问题本体、xml 如何组织模板与几何、两层配准如何发挥作用、缺陷如何沿测量集被逐点测出来,以及整套系统为什么能够在真实产线上跑起来。
但这些内容其实都默认了一件事:
模板已经存在。
而真实现场里,这恰恰不是理所当然的。
模板不是从天上掉下来的,也不是在原图上随手框一个区域、截一张图就能直接拿来用。对这套系统来说,模板必须先被生产出来,而且要被生产成一种能够进入后续检测链的结构对象:它要能被验证、能被修正、能被保存、能被标准化组织,最后还要能稳定地进入 xml、csv 和参数链。
也正因为如此,我一直觉得,这套系统真正容易被忽略的一层,不是检测函数本身,而是模板生产链。很多人谈工业检测时,只盯着“最后怎么判 NG”,却很少追问:这些后续检测所依赖的骨架、中心点、局部结构模板,最开始到底是怎么来的?如果这一层没有被可靠建立起来,后面的配准、测量和缺陷判定,其实都失去了稳定起点。
这一篇,我就想把这条线单独讲清楚:
- 为什么模板不是“截图”这么简单;
- 模板创建工具真正解决了什么问题;
- 为什么模板必须先经过验证、修正和标准化保存,才能进入后续检测链;
- 为什么模板生产链本身就是这套系统能力的一部分。
一、为什么模板不是“截图”这么简单
如果只从表面看,模板创建这件事似乎很容易被理解成:打开一张图片,框出一个字符区域,然后存起来,供后面做匹配或检测使用。
但对这套系统来说,这样的理解太浅了。
因为这里的模板并不是一张单纯拿来参考的图片,而是后续配准、测量和缺陷判定的起点。它不仅要告诉系统“这个局部结构长什么样”,还要进一步提供骨骼点、中心点以及与 block、Geo、注册集、测量集相衔接的结构信息。也就是说,在这套系统里,模板不是视觉参考,而是一个会继续进入检测链的结构对象。
一旦把这一点看清楚,很多事情就会自然变得不同。模板创建不再只是“把图截出来”,而必须回答更严格的问题:这个局部区域是否足够干净?骨架是否可信?中心点是否正确?噪点是否已经剔除?保存出来的数据,后面能否被 xml、csv 和参数系统稳定接住?
所以,从这个意义上说,模板不是截图,而是模板生产链输出的结构对象;而这个结构对象最终如何被组织成后续配准的最小单元,又会继续决定检测的稳定性。
二、模板创建工具真正解决了什么问题
这套系统后来之所以能跨产品、跨国别、跨产线复用,一个很重要的原因,就是模板并不是靠人手工零散拼出来的,而是已经被纳入了一条相对完整的生产链。模板创建工具的意义,也恰恰在这里。
从工具文档可以看得很清楚,这个工具较上一版增加了矩形框标注、中心点自动生成、中心点自动保存为标准格式等功能;在实际使用时,先输入单张源图像,再显示算法处理后的二值图像,而不是直接停留在原始灰度图上。之所以优先显示二值图,是为了让模板创建者能够更清楚地查看局部结构,并判断模板是否有效。
也就是说,这个工具首先解决的,不是“怎么方便地截个图”,而是:
- 模板区域如何被可靠截取;
- 模板是否可信,如何被验证;
- 模板如何进一步变成后续系统可用的标准化数据。
一旦把这个工具放回整个检测链来看,它的地位就会很清楚:它不是一个附属小工具,而是模板生产链的入口。
三、为什么“处理后的二值图”比原图更重要
模板创建工具里有一个很关键的设计:在打开原始灰度图像之后,界面上优先呈现的并不是原图本身,而是算法处理后的二值图像。
这件事表面上看只是显示方式的选择,但其实非常能说明模板创建的立场。因为在这套系统里,模板并不是给人“看着像不像”的视觉参考图,而是后续骨架提取、中心点生成、配准与测量的上游输入。真正需要被确认的,并不是原图在视觉上是否清楚,而是这个局部区域经过算法处理之后,是否还能稳定地保留出后续检测真正依赖的结构信息。
也就是说,模板创建并不是站在人眼直观的层面上判断“这个字符看起来像不像”,而是站在后续检测链的层面上判断:这个局部区域是否足够干净,二值结果是否足够稳定,骨架是否有机会被可靠抽取,中心点和结构点能否被进一步组织成可进入 xml 与 csv 的标准化对象。
从这个意义上说,二值图之所以比原图更重要,并不是因为它在视觉上更简洁,而是因为它离后续检测真正使用的结构层更近。模板创建从一开始就不是视觉截图,而是在做面向检测链的结构确认。
四、为什么要有骨骼点可视化和噪点删除
如果模板只是图像块,那么截出来保存即可;但如果模板要作为后续检测链的结构对象,它就不能只停留在图像块层面,而必须进一步进入骨架与中心点层面。
这也是为什么工具里会有骨骼点可视化功能。文档里明确提到,经算法处理后的骨骼点骨架图会在界面上显示出来,目的是让使用者能够判断模板是否可信。对于英文阿拉伯字符,骨骼点坐标会存储到 xml 文件中,中心点坐标会以标准格式存储到 csv 文件中;对于中韩等字符,中心点同样会以标准格式输出。
这说明模板创建并不是“一次性自动完成”的,而是一种半自动的人机协同过程。算法先把局部结构抽出来,工具再把骨架可视化,让人去判断这个模板是否值得保留。更进一步,当模板中存在干扰点时,工具还支持通过鼠标右键框选删除噪点,并在删除后自动保存骨骼点数据,以提高模板质量。
也就是说,这套系统里的模板质量,并不是靠“算法一次性输出完美结果”来保证的,而是通过可视化、人工修正和标准化保存共同保证的。
五、为什么模板创建不是自动导出,而是一条高门槛的半自动生产链
如果只看工具界面,模板创建似乎只是打开图像、框选 AOI、保存数据而已。但对这套系统来说,真实情况并不是这样。模板创建并不是一个自动导出步骤,而是一条强依赖实施工程师参与的半自动生产链。
首先,模板本身就不是简单截图。模板创建工具文档已经说明,打开原始灰度图之后,界面优先显示的是算法处理后的二值图,而不是原图本身;这样做的目的,是为了通过二值图清晰查看并确保模板是否有效。对于英文阿拉伯字符,工具会把骨骼点坐标存入 xml、中心点坐标以标准格式存入 csv;对于中韩等字符,则至少会把中心点标准化输出。也就是说,这里的模板从一开始就不是视觉参考图,而是后续检测链中的结构数据对象。
如果把这条过程压缩成一条更直观的链,它大致可以表示为下面这样:
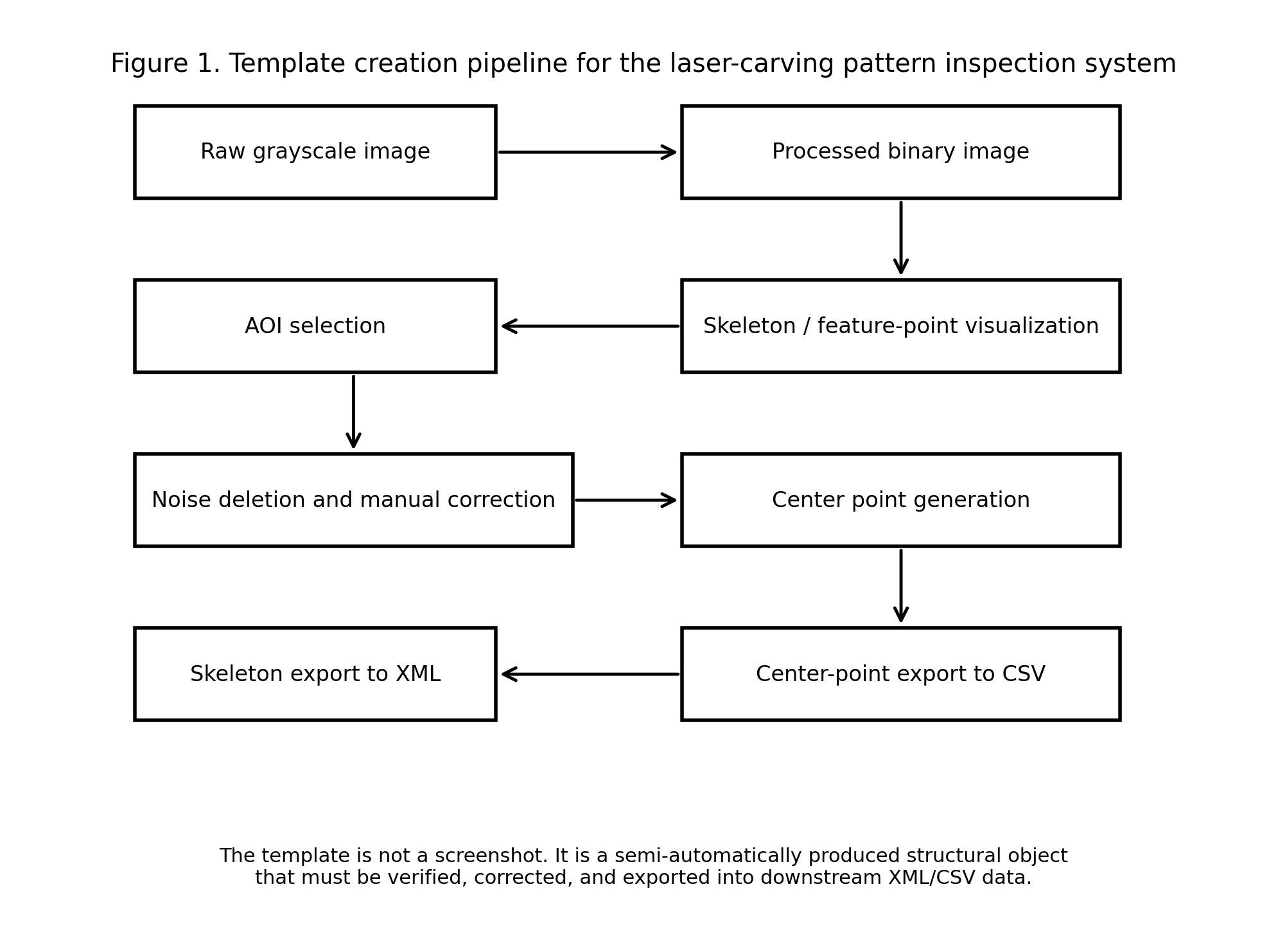
图 1:模板创建链流程图。模板并不是从原图中随手截取的图块,而是经过二值图确认、AOI 标注、骨架/特征点可视化、删噪修正以及 XML/CSV 导出之后,才能进入后续检测链的结构对象。
更进一步看,这里的模板甚至不能简单理解成“一个局部图块加若干附属点”。在这套系统里,模板是会真正进入 xml 的结构对象。最直观的形式,就是 character 下的 skeleton 节点。例如,在实际模板文件里,可以看到类似下面这样的结构:
<character>
<skeleton name="L" size="30" genus="1">
<p x="1534" y="322" />
<p x="1535" y="326" />
<p x="1535" y="330" />
<!-- ... -->
</skeleton>
<skeleton name="vci" size="1104" genus="1">
<p x="522" y="30" />
<p x="527" y="30" />
<p x="479" y="31" />
<!-- ... -->
</skeleton>
</character>
这里最值得注意的,并不是 p(x,y) 这些点本身,而是:不同类型的检测对象——字符、logo、实心区域 pattern 等——都会以类似形式进入模板层。也就是说,skeleton 在 xml 里首先是一个统一的模板容器,而不是对几何对象类型的严格限定。
也正因为如此,skeleton 这个名字其实很容易让人误解。详细设计文档已经明确指出:skeleton 名义上虽然叫 skeleton,但实际上并不一定就是严格意义上的 skeleton,也可以是各种类型的特征点。换句话说,这一层的真正作用,并不是给对象贴一个几何学名词,而是把后续配准与测量所需要的结构点集合统一组织进模板文件。
对枝杈结构,例如英文字符,这类模板更接近 medial axis 一类的中轴特征;而对实心区域 pattern,则需要用另一类特征提取方式。到了检测阶段,这种差异会进一步体现在注册集和测量集的组织上:枝杈结构的注册集和测量集可以都取 medial axis,而实心结构的注册集则是边缘点集合,测量集是内点集合。也就是说,medial axis 和实心区域 pattern 本来就是两类不同对象,它们并不依赖同一种模板生成算法。
这条链并不是纸上抽象流程,而是被具体工具支撑起来的。下面这张局部界面图可以更直观地说明:模板创建同时包含图像确认、骨架判读、删噪修正和结构数据导出等环节。
图 2: 模板创建工具的局部界面示意。工具并不只是完成图像截取,还提供二值图确认、骨架可视化、删噪修正和结构数据导出等功能,从而把模板创建变成一条可验证、可修正、可保存的半自动生产链。
这件事之所以必须强调,是因为它直接决定了模板创建并不是“会点工具就行”。实施工程师不仅要会框 AOI、会保存 xml 和 csv,更要理解:当前面对的到底是哪一类对象,骨架生成算法输出出来的点集在几何上意味着什么,哪些点是可信结构,哪些只是噪声。如果把这件事理解错了,那么后面的骨骼点可视化、删噪、参数调节和模板保存都会变成机械操作,而机械操作恰恰最容易把错误带进后续检测链。
而且,这条模板生产链并不只停留在“把骨架点存出来”这一步。模板是否可信,必须通过处理后的二值图与骨架图共同判断:二值结果决定局部结构是否被稳定提取,骨架结果决定这些结构能否进一步进入后续配准与测量。对于干扰点较多的局部区域,工具允许通过右键框选直接删除噪点,以提高模板质量;缩放因子和 blocksize 也都可以调整,分别影响匹配效率与二值化效果。
这说明工具真正做的,并不是“一键导出模板”,而是把模板创建过程中那些会实质影响质量的判断点显式暴露出来,让实施工程师参与确认、修正和收敛。模板创建因此不是一次自动输出,而是一条半自动的人机协同生产链。
这也正是模板创建门槛高的地方。实施工程师真正面对的问题,并不是“会不会用界面”,而是:
- 能不能判断
AOI是否合理; - 能不能看懂骨架质量;
- 能不能分辨哪些点属于结构本体,哪些只是噪声;
- 能不能理解阈值和参数会怎样影响后续骨架生成与检测结果。
骨架点一旦生成不好,后面的漏检和过杀就会被直接带进系统;而 ini 和 XML 即便能够自动生成,也并不意味着配置已经合格。真正可上线的配置,仍然需要拿现场 CCD 采集图在实验室调试,再到产线继续收敛,直到最终上线。也就是说,模板创建工具只是模板生产链的入口,而不是整条链的终点。
从这个意义上说,这条链真正缺的并不是普通意义上的“实施人员”,而是贴近现场的应用算法工程师。这样的人既要愿意长期做现场,又要有足够的图像处理理解力、经验和责任心;稍有能力的人往往不愿长期承担这类又细又重的工作,而能力不足的人又承载不起模板质量和参数质量。对这套系统而言,这恰恰是后来推广困难的核心原因之一:不是系统主线不成立,而是模板生产链和参数闭环链对人的要求太高,而组织层面对这一岗位的定义、权限和资源未必匹配。
所以,如果要把这一节压缩成一句话,我更愿意这样说:
模板创建并不是检测系统之外的准备动作,而是一条强依赖实施工程师能力的半自动生产链;而这条链的质量,直接决定了后续配准、测量以及最终漏检和过杀的水平。
六、为什么模板生产不仅在“提点”,更在决定配准单元如何组织
模板生产链里还有一个特别关键、但前面一直没有单独展开的问题:模板并不只是“把骨架点提出来”就结束了,更重要的是,这些点最终按什么单元进入 xml,决定了后续配准的稳定性。
在这套系统里,skeleton 名义上看像是在存某个字符或某个局部图样的结构点,但从检测链条来看,它首先对应的是一个更本质的角色:配准的最小单元。而这个最小单元,并不总是“一个字符对应一个 skeleton”。有时候,一个字符会单独形成一个 skeleton;有时候,多个字符或多个局部结构会被合并成同一个 skeleton。这并不是模板命名方式上的随意变化,而是模板生产阶段就必须做出的几何决策。
单个字符作为一个 skeleton 的好处,是局部定位更细,配准质量往往更高,也更不容易漏掉局部字符本身;但它也有代价:当对象本身过于简单、拓扑约束过弱时,非刚性配准有可能把真实缺陷“吸收进形变里”。例如,对字符 1 这样结构相对单薄的对象,即使原图中已经少掉一段,模板在配准时仍然可能被平滑地拉过去,看上去“配准成功”,从而在现场形成漏检。
相反,带有环柄、闭合回路或更强整体结构约束的对象,例如 B、6 一类字符,通常会更稳定。这种稳定性并不只是因为它们“更复杂”,而是因为环柄或闭合结构会给非刚性配准提供更强的整体约束:模板不再容易靠局部平滑形变去掩盖真实缺损,局部 break 也更难被整体形变无代价地吞掉。换句话说,拓扑结构本身会直接影响配准的鲁棒性与漏检风险。
而对于汉字、不规则图形,或者那些单独拿出来拓扑结构不够强的局部对象,这种风险则可以通过另一种方式缓解:把多个字符或多个局部结构合并为同一个 skeleton。这样做的意义,不只是“多放一些点”,而是在模板层面人为增强整体几何约束,使配准时不再只盯住一个过于脆弱的小对象,而是面对一个更完整、更稳定的结构单元。这样一来,虽然单点级别的自由度下降了一些,但整体配准更不容易失败,也更不容易因为局部缺损而被非刚性形变掩盖。
所以,模板生产链真正难的地方,并不只是骨架提取、删噪和标准化保存,还在于:必须根据对象的几何与拓扑特征,决定什么样的 skeleton 才适合作为后续配准的最小单元。从这个意义上说,模板生产并不是单纯的数据导出过程,而是已经在为后续检测的鲁棒性、漏检率和过杀率预先做结构设计。
七、为什么缩放因子和 blocksize 不是小参数,而是模板生产的一部分
还有两个看似不起眼、但其实很能说明模板生产链成熟度的点,就是缩放因子和 blocksize 参数。
文档里明确写到:缩放因子设置范围为 0 到 1,可以提高字符匹配速度;而 blocksize 二值化参数则可以调整二值化效果。更重要的是,修改缩放因子后,需要重新打开图像才能实现参数加载。
这说明这些参数并不只是界面上的附属选项,而是直接参与模板质量与后续检测效率之间的平衡。缩放因子影响的是模板进入检测时的速度,blocksize 影响的是模板生产时的结构可判读性。换句话说,这些参数虽然出现在模板创建工具里,但本质上仍然属于模板生产链的一部分。
八、所以,这条模板创建链本身就是系统能力
把这些环节放在一起再看,就会发现:模板创建工具并不是一个“小工具”,而是在做一件很完整的事情。
它把:
- 原始图像读取;
- 二值图确认;
AOI区域标注;- 骨骼点可视化;
- 中心点自动生成;
- 噪点人工修正;
- 标准化保存输出;
- 配准单元组织决策;
连成了一条模板生产链。
而没有这条链,后面的 xml、配准、测量、缺陷判定和现场实施,其实都缺少一个稳定起点。也正因为如此,我越来越觉得,这套系统里真正容易被低估的,不只是检测算法,而是这种模板如何被可靠生产出来的能力。
所以,如果要把这一篇压缩成一句话,我更愿意这样说:
模板不是检测系统之外的准备工作,而是整套系统最上游的生产机制;它不仅生产点集,还在生产后续配准所依赖的最小结构单元。
九、这一篇的结尾:模板不是死的,下一篇继续讲“局部几何修正”
到这里,这条模板生产链其实已经比较清楚了:模板不是随手截出来的图块,而是经过验证、修正、标准化保存之后,才能进入后续检测链的结构对象。
但真实现场里,模板并不是一旦入库就永远不动。很多时候,局部区域仍然需要进一步屏蔽、擦除或几何修正,才能更稳定地适配具体产品和具体现场。
所以下一讲,我想继续沿着这里往下写:
为什么模板不是死的——
eraseSet与局部几何修正机制到底在解决什么问题。