第六讲:曲面 Pattern 检测系统为什么能在产线上稳定跑起来——节拍、并行与配置路由
Why This Curved-Surface Pattern Inspection System Can Run Stably on Production Lines: Takt Time, Parallelism, and Configuration Routing
English Abstract
This article explains why the system can run stably on real production lines after the detection logic has already been established. The key lies not only in whether defects can be measured, but in how configurations are routed, how tasks are organized, how takt-time constraints are satisfied, and how the implementation layer is made operational. In this sense, a real industrial system must not only detect correctly, but also know how to load the right configuration, execute within cycle time, and remain maintainable in deployment.
在前一篇里,我主要讨论了模板落位之后,缺陷是如何沿着测量集被逐点测出来的。到那一步为止,这套系统已经回答了一个核心检测问题:它不是在整张图里盲目寻找异常,而是在模板已经进入实测图像、测量点已经落位之后,沿着结构关系去感知局部偏差。
但检测逻辑成立,还不等于系统就能在产线上稳定工作。
真正的工业系统,除了要“能检出来”,还必须回答另外几个同样现实的问题:它如何知道这次该加载哪一套配置?不同产品、不同国别、不同图档之间如何切换?检测如何满足产线节拍?为什么便宜的上位机也能把整套流程跑起来?以及,为什么实施层不是简单地点点工具,而是一层真正的系统能力?
到这里,问题已经不再只是“能不能检出来”,而变成了:这套检测能力能否被真正组织进一条持续运行的工业流程里。
如果说前面的模板、配准和测量层构成了这套系统的检测主干,那么这一篇要进入的,就是它的运行主干:配置如何被路由进来,任务如何被组织起来,节拍如何被保证,以及实施层为什么本身就是系统能力的一部分。
所以,这一篇真正要讲清楚的是:
- 为什么工业系统的关键不只是“能检出来”,而是“能稳定跑起来”;
- 系统如何知道当前该加载哪一套产品 / 国别配置;
- 为什么换产品时主要改的是配置,而不是核心代码;
- 为什么 block 级组织、多线程和实施工具链对节拍与落地至关重要。
一、为什么工业系统的关键不只是“能检出来”,而是“能稳定跑起来”
很多算法在实验室里都能跑出结果,但真正到了产线,问题会立刻变得不一样。产线不会只关心“这次有没有检出来”,它更关心的是:下一次还稳不稳、换一批产品还行不行、节拍顶不顶得住、现场人员能不能接得住。
这就是为什么我一直觉得,工业算法真正难的,不只是把结果做出来,而是把它放进一条持续运行的生产流程里。
对于这套系统来说,这一点尤其明显。因为它面对的不是单一图像,而是一套要长期服务于不同产品、不同国别、不同图档、不同实施人员和不同节拍要求的检测链。也就是说,它必须同时满足几件事:
- 检出能力要成立;
- 配置切换要顺畅;
- 运行速度要满足节拍;
- 系统行为要足够稳定;
- 现场实施要可操作、可维护。
如果这些条件只能偶尔满足一部分,那么这个系统就还算不上真正的工业系统。
从这个意义上说,“能跑起来”并不是一个比“能检出来”更低级的问题,恰恰相反,它往往更接近系统成熟度本身。
二、系统是怎么知道“这次该加载哪一套配置”的
如果核心 DLL 并没有针对每一个产品、每一个国别都写一套独立代码,那么系统首先就必须回答一个更上层的问题:当前这一轮检测,到底该进入哪一套配置链?
这件事并不是靠人工在代码里改路径来实现的,而是通过一层更轻量级的配置路由机制来完成。也就是说,在真正进入 ini、xml 和模板图之前,系统上方其实还有一层负责“分发配置”的入口。这个入口层最直观的体现,就是 CarvingPatternType.xml。
它本身并不存具体模板结构,也不直接参与缺陷检测逻辑,而是先根据某个 pattern 名称或方案 ID,把系统导向对应的配置入口,也就是某一份 LaserCarvingPatt.ini。下面这份实际配置已经能很清楚地说明这一点:
<?xml version="1.0" encoding="utf-8" ?>
<entity>
<pattern name="AM" id="635">
<path name="ini" value=".\lab_config\AM\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="BE" id="636">
<path name="ini" value=".\lab_config\BE\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="LZ" id="642">
<path name="ini" value=".\lab_config\BE\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="CH" id="637">
<path name="ini" value=".\lab_config\CH\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="ID" id="639">
<path name="ini" value=".\lab_config\ID\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="KH" id="641">
<path name="ini" value=".\lab_config\KH\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="TA" id="644">
<path name="ini" value=".\lab_config\TA\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="ZM" id="650">
<path name="ini" value=".\lab_config\ZM\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="HN" id="638">
<path name="ini" value=".\lab_config\ZM\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="VN" id="647">
<path name="ini" value=".\lab_config\ZM\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="RU" id="643">
<path name="ini" value=".\lab_config\ZM\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="TY" id="646">
<path name="ini" value=".\lab_config\ZM\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="ZA" id="648">
<path name="ini" value=".\lab_config\ZM\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="ZE" id="649">
<path name="ini" value=".\lab_config\ZM\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="TU" id="645">
<path name="ini" value=".\lab_config\ZM\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="ZP" id="651">
<path name="ini" value=".\lab_config\ZM\LaserCarvingPatt.ini"/>
</pattern>
<pattern name="J" id="640">
<path name="ini" value=".\lab_config\AM\LaserCarvingPatt.ini"/>
</pattern>
</entity>
这份文件最值得注意的地方,不只是“系统能够根据代码找到对应 ini”,而是它已经明显体现出一种配置族式的复用关系。也就是说,这里并不是每个国别或方案代码都独占一套完全独立的配置,而是允许多个不同代码被路由到同一份 LaserCarvingPatt.ini。例如,AM 与 J 共享同一入口,BE 与 LZ 共享同一入口,而 ZM 则进一步承接了多个不同代码的配置入口。
这说明系统在更上层已经做了归类:不同代码未必对应完全不同的检测逻辑,它们可以先在路由层被归并到少量共享配置族中,再由对应 ini 继续挂接 xml、bmp 与参数文件。于是,对核心 DLL 来说,它并不需要知道“当前是哪个国别、该去找哪张图、该进哪份 xml”,它只需要沿着这条外部配置链去加载当前方案即可。
从系统架构的角度看,这一点非常重要。因为它说明这套系统的复用能力,不只是建立在 xml + ini + bmp 这些外部描述层之上,在它们之上其实还有一层更轻量级的配置路由机制。也正因为有了这一层,系统在面对不同产品、不同国别和不同图档时,才不需要从 DLL 开始重新改动,而是可以先通过路由层进入正确的配置链,再由后续的参数、模板和图档去承接具体差异。
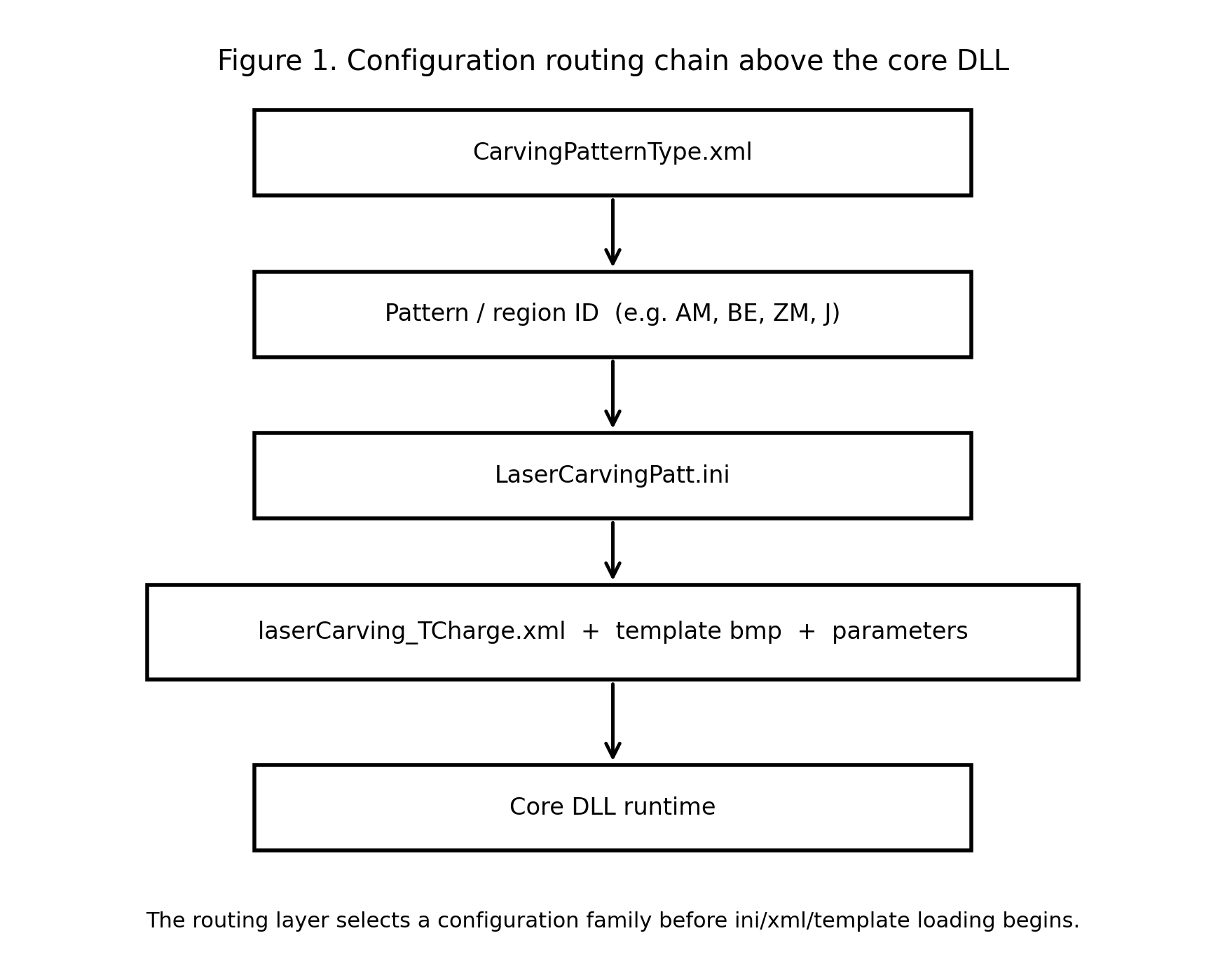
图 1:配置路由链条图。
系统并不是直接进入某个固定 ini 或 xml,而是先通过顶层路由层选择当前方案所属的配置族,再进入后续的 ini、模板与参数链。
三、为什么换产品时主要改的是配置,而不是核心代码
如果只从外部看,很多人会以为系统之所以能复用,主要靠的是“代码写得比较通用”。但真正做过的人会知道,事情并不是这样。
这套系统真正的复用能力,来自于设计阶段就把变化压缩进了外部描述层。也就是说,真正会随着产品、国别和图档变化而变化的东西,并没有被埋进 DLL 里,而是被拆到更外层的配置链条中去承接:
- 顶层路由决定进入哪一套方案;
ini决定当前方案的参数、检测类型和运行方式;xml决定模板、几何锚点、block 组织和容错规则;bmp决定图档入口和模板底图。
于是,对核心 DLL 来说,变化并不是“每来一个新产品就加一套新逻辑”,而是“按新的外部描述重新组织同一套检测能力”。
这件事真正厉害的地方,不只是把路径写到配置文件里,而是把“变化本身”做了层级化拆分。最上层先回答“该进哪一套配置族”,中间层再回答“这套方案的参数和运行方式是什么”,更下层才回答“模板、几何和图档长什么样”。这样一来,系统面对新产品、新国别或新图档时,并不需要一次性从底层代码开始重写,而是可以优先在外部配置链中完成切换。
这也解释了为什么换产品时主要改的是配置,而不是核心代码。因为对一个真正成熟的工业系统来说,最理想的状态并不是“代码足够万能”,而是“代码尽量稳定,变化被成功约束到外部描述层”。只有这样,系统才可能长期活下来;否则,一旦每次换产品都要改 DLL、重新编译、重新验证,系统的维护成本很快就会失控。
所以,换产品时主要改配置而不是改代码,并不是一个“省事一点”的工程细节,而恰恰是这套系统成熟度的重要体现。它说明这套系统已经不只是能跑,而是已经形成了一条相对清楚的外部配置体系:由路由层选择方案,由参数层控制行为,由模板层承接结构差异,由图档层提供入口对象,而核心 DLL 尽量保持稳定。
四、为什么 block 级组织、多线程和任务拆分对节拍至关重要
工业系统不仅要“对”,还要“快”。而这套系统能够在真实现场满足节拍,一个非常关键的原因,就是它从一开始就不是按“整张图串行慢慢跑”的思路组织的。
前面几讲已经讲过,系统在检测逻辑上本来就是按 block 来组织的。每个 block 都有自己的模板结构、自己的注册集和测量集,也有各自的局部检测任务。正因为如此,这种结构天然适合进一步被拆成并行任务。
但这里真正有分量的,并不只是“用了多线程”这件事,而是它在数据组织上也同时做了适合并行执行的设计。系统并没有把所有检测任务的中间结果都塞进一个共享容器里,再靠锁去协调谁先写、谁后写;相反,它从一开始就把 block 编号与对应的数据槽位静态绑定起来。每个 block 对应独立的测量数据、模板数据、结果数据和完成标志,线程只需要按 block 编号读写各自的固定内存槽位即可。
这种静态定址映射并不是抽象说法,在实现层上,它就是类似下面这样的代码结构:
inline void getmeasuredata(RegistModel *&rm, int i)
{
switch (i)
{
case 1: rm = &measuredData1; break;
case 2: rm = &measuredData2; break;
case 3: rm = &measuredData3; break;
// ...
case 80: rm = &measuredData80; break;
}
}
inline void assignmeasureddata(RegistModel &rm, int i)
{
switch (i)
{
case 1: measuredData1 = rm; break;
case 2: measuredData2 = rm; break;
case 3: measuredData3 = rm; break;
// ...
case 80: measuredData80 = rm; break;
}
}
这类代码表面上看只是一个很长的 switch-case,但从运行层角度看,它做的是一件非常工程化的事情:把每个 block 与其对应的测量数据、结果数据和完成标志做静态定址映射。一旦这种映射建立起来,线程在主检测路径上就不需要围绕共享结果容器竞争写入权,也不需要为了中间结果回收和合并频繁进入临界区。换句话说,这里看似朴素的实现,背后对应的其实是一种以空间换同步、以预分配换锁竞争的并行组织方式。
与此同时,原始灰度图只保留一份,各线程按需获取对应 block 的 ROI 视图,而不是为每个任务重复复制整张图像。这样做有两个直接好处:一是节省了内存复制成本,二是让并行任务的启动与执行开销维持在较低水平。也就是说,这套系统的快,不只是来自检测函数本身,更来自它在更上层就已经把任务拆分方式和数据流组织对了。
从这个意义上说,这套系统的多线程并不是后期为了提速临时加上的优化,而更接近它从结构设计上自然长出来的运行能力。主检测框架在绝大多数 block 上实现的是零同步开销的并行执行:各线程按 block 独立处理、独立落位、独立写回,不需要显式共享写入协调。也正因为如此,在便宜的上位机上,整套检测链仍然有机会压进产线可接受的节拍内。前面提到的那个结果之所以有分量——一个四十多个字符的镭雕检测只需要约 400ms——真正起作用的,并不只是某个局部函数写得快,而是系统在更上层就已经完成了正确的任务组织。
当然,这并不意味着所有 block 在任何情况下都完全等价。对少数存在空间重叠或局部写入耦合的 block,线程执行顺序会带来工程上的次级影响。这里要强调的是,这种影响并不是主检测框架的常态,也不是系统成立所依赖的理论前提,而更接近于现场实现层中的特殊现象:在某些局部重叠情形下,不同线程先后作用于局部区域,可能会带来略有差异的现场效果。后来现场实施中甚至总结出了一些顺序经验,这恰恰说明系统进入真实产线后,还会与具体产品布局和局部几何关系进一步发生作用。
所以,如果要把这一节压缩成一句话,我更愿意这样说:
这套系统之所以能在真实现场满足节拍,不只是因为检测逻辑成立,更因为它在
block级任务拆分、固定槽位内存映射和零同步开销并行执行上,已经提前长成了一套适合工业运行的结构。
五、为什么真正高性价比的提速点在上位机,而不是算法核
很多人在看到产线节拍压力时,第一反应往往是继续要求算法提速。但对这套系统来说,这种直觉并不总是对的。原因并不是算法不重要,而是当算法核本身已经做了并行化、线程间临界区已经压到极小之后,继续从算法内部硬挤效率,边际收益会越来越低;这时,真正更高性价比的提速点,往往已经转移到了上位机架构。
这里真正需要分清的是:算法速度和系统吞吐并不是同一个问题。算法核本身已经采用 C++ 并行实现,线程间同步开销很小,继续从算法内部提速的空间其实有限;而上位机侧却仍然把 PLC 通信、图像采集、算法处理和结果显示组织成一条串行链,后一步必须等待前一步结束。结果就是,系统虽然在算法核内部已经很快,但在整条运行链上仍然会不断出现等待,从而把原本可以利用的生产间隙浪费掉。
从系统角度看,这就意味着:节拍上限并不只由算法核决定,而是由整套任务调度架构共同决定。只要平台侧仍然把采图、算法、显示和通信锁成一条串行链,那么算法即使再快,整体吞吐也仍然会被系统架构吞掉。
也正因为如此,更合理的方向不是继续要求算法单点提速,而是修改上位机架构,把原本串行执行的几段流程解耦开来。对此,我当时提出的方案是“双缓存三线程”结构:一个图像队列、一个结果队列,相机线程负责把采集到的图像送入图像队列,算法线程从图像队列中取图处理,再把结果写入结果队列,通信线程则从结果队列取回结果并返回控制单元与显示器。这样一来,采图、计算和回传不再被锁成一条单链,而是可以在生产间隙中并行推进。
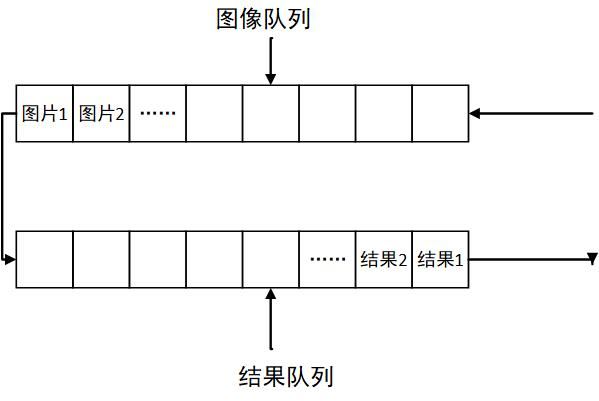
图 3: 双缓存三线程结构示意图。相机线程先将图像送入图像队列,算法线程异步完成检测,再把结果写入结果队列,通信线程从结果队列中回传结果并负责显示。它真正解决的不是某个局部函数是否更快,而是如何把原本串行的系统吞吐重新组织起来。
如果把这一层压缩成一句话,我更愿意这样说:
当算法核已经接近自身效率上限时,真正决定系统节拍的,往往不再是算法本身,而是上位机是否愿意围绕并行检测去重写运行架构。
六、为什么实施层不是“点点工具就行”,而是一层真正的系统能力
很多外人一看到实施工程师在现场框框 AOI、调调参数、删删噪点,就容易误以为这部分工作没有多少技术含量,仿佛只是把算法系统“点开”而已。但只要真正看过模板创建工具的使用方式,就会知道,这种理解其实很浅。工具表面上提供的是框选、可视化、保存、删点、调缩放因子和二值化参数等操作,但这些操作背后对应的,并不是机械点击,而是一层半自动的人机协同建模过程。模板创建工具会把原始图像处理成便于判读的二值图,支持 AOI 标注、骨骼点可视化、中心点自动生成与标准化保存,也允许对骨架中的干扰点进行人工删除,以提高模板质量。
这说明实施层真正面对的问题,并不是“会不会用界面”,而是:能不能判断一个模板是否可信,能不能分辨哪些骨骼点属于结构本体、哪些只是噪点,能不能理解缩放因子和二值化参数会怎样影响后续匹配速度与模板质量。换句话说,实施层并不是在替算法做一些琐碎劳动,而是在协助系统完成模板生产、模板验证和模板标准化入库。
从系统角度看,这一点非常关键。因为前面几讲讲到的 xml 模板、注册集、测量集、block 组织和局部缺陷测量,都不是凭空存在的,它们最终都要落到具体模板对象上。如果实施层无法稳定地生产出可信模板,那么前面的结构化检测主线就会从源头开始失真。也正因为如此,实施工程师培养才会难:愿意做的人未必真正理解骨架、中心点、局部结构和参数之间的关系;而理解这些关系的人,又未必愿意长期做贴近现场、反复打磨模板与配置的工作。
所以,这里真正值得强调的,不是“实施很麻烦”,而是:
实施本身就是系统能力的一部分。
没有这一层,前面的模板组织、分层配准和局部测量机制,就很难被可靠地迁移到新产品和新产线上;而只有当模板创建、模板验证、参数承接和现场导入形成了稳定流程,这套系统才算真正具备了可落地、可复制、可继承的工业形态。
从这个意义上说,实施层并不是检测系统之外的一圈“人工补丁”,而是把检测层、配置层和现场导入层真正接起来的那一层。也正因为如此,这套系统能够跨产品、跨国别、跨产线持续工作,靠的从来不只是核心 DLL 或某个局部算法,而是连模板工具、实施流程和现场经验一起,被组织进了同一套系统能力之中。
七、为什么这套系统能在真实现场长期稳定工作
如果把前面的内容合起来,其实就能看清一件事:这套系统之所以能在真实现场长期稳定运行,并不是因为某一个模块特别强,而是因为检测层、配置层、调度层和实施层被组织成了同一套系统。
- 检测层回答“能不能检出来”;
- 配置层回答“该加载哪一套方案”;
- 调度层回答“如何在节拍内把任务跑完”;
- 实施层回答“模板和配置如何在现场被可靠生产和继承”。
只有这几层同时成立,系统才会从“一个能跑通的算法”变成“一个能长期工作的工业对象”。
这也是为什么我始终不太认同把这类项目理解成“某个检测算法做得不错”这么简单。因为真正决定系统寿命的,往往不是某个局部指标,而是这些不同层级之间能不能咬合起来:配置路由是否清楚,模板对象是否稳定,检测主线是否可复用,并行组织是否能压进节拍,实施层是否能持续接住。缺了其中任何一层,系统都可能在真实现场很快失去稳定性。
从这个意义上说,这套系统真正可贵的地方,不只是它当年在某个项目里做成了,而是它已经形成了一条相对完整的工业技术链:从配置路由,到模板组织,到配准测量,到并行运行,再到现场实施和维护,都被纳入了同一条方法主线之中。也正因为如此,它的稳定运行不是偶然结果,而是一种系统结构自然导出的结果。
如果一定要把这一层再压缩成一句话,我更愿意这样说:
这套系统之所以能长期稳定工作,不是因为某个模块“特别强”,而是因为检测层、配置层、调度层和实施层被真正组织成了一套相互支撑的系统。
八、这一篇的结尾:从“它为什么能跑起来”回到“它为什么值得被重述”
写到这里其实可以看清,这套系统之所以值得我反复写,并不仅仅是因为它能检出某几类缺陷,或者在某些实验里效果不错,而是因为它在当时已经具备了比较完整的工业系统形态。
它不是一个悬空的算法模块,
也不是一个只在实验室里成立的 demo,
而是一套能够知道该加载哪套配置、如何在节拍里运行、如何被实施层接住并在现场持续工作的系统。
所以,如果要为这一篇压缩成一句话,我更愿意这样说:
真正的工业系统,不只是能检出来,还必须知道该加载哪套配置、怎样在节拍内跑完,以及如何让实施层接得住。
到这里,这个系列其实已经走完了它最核心的前半段:问题是什么,系统怎样组织,模板如何建立,配准如何发挥作用,缺陷如何被测出来,以及它为什么能在真实产线上跑起来。
如果后面继续写,我更愿意进一步写两类内容。
一类是回到更高层,讨论为什么这类项目不应该被草率地理解成“普通字符检测”,以及为什么真正做成过的系统,值得被重新表述成一个可传递的技术对象。
另一类则是回到我自己的研究线,讨论这类工业系统如何反过来影响了我后来在点集配准、结构化表示和几何算法上的思考。
也就是说,到这一篇为止,这个系列已经不再只是对某个旧项目的回忆,而开始逐渐显露出它更重要的意义:它不是为了证明我做过什么,而是为了把一个真正成立过的工业算法系统,重新还原成一个能够被别人理解、检验和继承的技术对象。