第五讲:曲面 Pattern 缺陷是怎么被测出来的——从模板落位到缺陷判定
How Curved-Surface Pattern Defects Are Actually Measured: From Template Alignment to Defect Decision
English Abstract
This article explains how defect detection is actually carried out after template alignment. Once the measure set has been brought into the measured image, the system does not scan the whole bitmap blindly; instead, it performs point-wise local measurement along aligned structural points, records point-level abnormal responses, and then aggregates them into final defect regions and defect types. From this perspective, defects are not directly “found” in the image, but measured out of an already established geometric relation.
在前一篇里,我主要讨论了这套系统的核心几何机制:为什么不能跳过配准直接谈检测,为什么系统采用了两层配准,以及为什么注册集与测量集必须分工。到那一步为止,模板已经不再只是静态文件中的结构对象,而是已经通过配准真正进入了实测图像。也就是说,系统已经回答了“模板落在哪里”这个问题。
但这还不是检测结果。
真正的缺陷判定,并不是配准结束时自动给出来的。配准只是把模板和实测对象之间的几何关系建立起来,而后续检测真正依赖的,是已经落位的测量集。只有当测量点进入了正确位置,系统才可能沿着这些点展开局部观察,进而把局部结构偏差、灰度异常、宽度变化、残余区域等信息逐步转化成可判定的缺陷类型。
所以,这一篇真正要讲清楚的是:
- 为什么缺陷检测不能脱离测量集单独谈;
- 系统到底在“测”什么;
- 为什么它不是沿整张图漫扫,而是沿测量点逐点展开;
- 不同缺陷类型为什么能够被统一纳入同一套测量框架。
一、为什么缺陷检测不能脱离测量集单独谈
如果把问题理解得很浅,最容易形成的印象就是:检测系统面对一张图像,最终只需要回答“有没有缺陷”。但对这套系统来说,这样的理解仍然太粗。因为它真正面对的,并不是一张尚未组织的原始图像,而是一个已经经过模板组织、两层配准和局部落位之后的结构化检测对象。
也就是说,系统并不是先对整张图做全图异常扫描,再回头去解释这些异常到底落在什么字符、什么图样、什么局部结构上。它的路径正好相反:先有模板,先有几何关系,先有测量点,然后才沿着这些测量点去判断局部是否异常。
从这个意义上说,测量集并不是某种附属数据,而更接近后续缺陷检测的工作坐标系。只有当测量点已经进入正确位置,系统才知道“应该在什么地方看”“应该沿着什么结构看”“局部偏差应该如何解释”。一旦脱离了这一层,很多原本可测的细微缺陷,就会重新退化成位图层面的模糊差异。
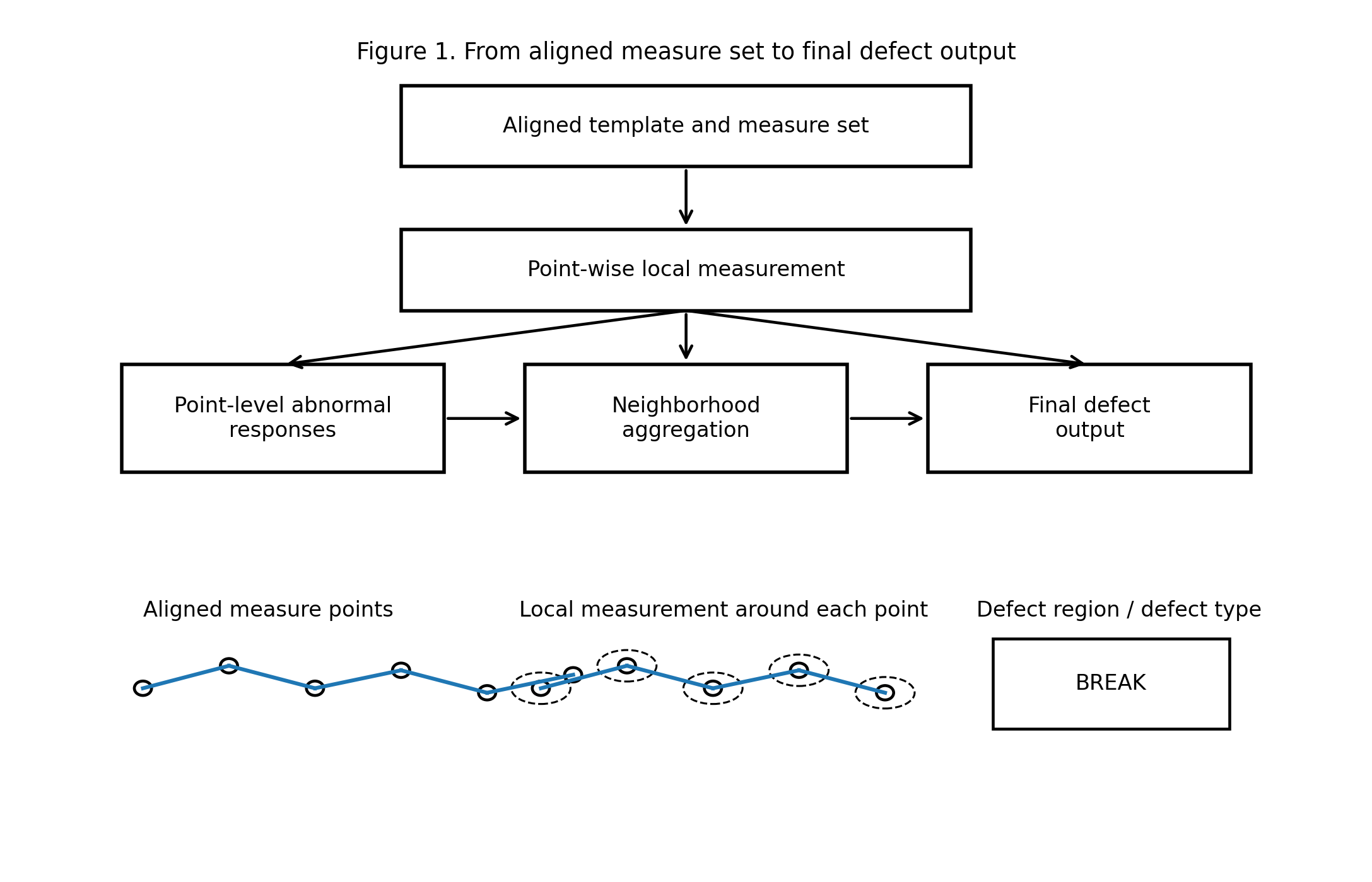
图 1:测量层总流程图。模板与测量集落位之后,系统沿测量点逐点展开局部测量,并将点级异常进一步组织为最终缺陷输出。
二、系统到底在“测”什么
当我们说“沿测量集做检测”时,真正发生的并不是某种抽象的“看一看周围是否正常”,而是一系列具体的局部测量。换句话说,这套系统不是在“猜缺陷”,而是在测一组明确的局部量。
从工程上看,这些局部量大致可以分成三类。
第一类,是局部灰度与对比关系。
这类测量主要对应色异常、局部发白发黑、填充状态异常等问题。系统并不满足于看某个点是亮还是暗,而是要看该点邻域的灰度区间、对比关系以及局部投影结构是否与应有 pattern 保持一致。
第二类,是局部宽度、断裂与连通状态。
这类测量主要对应镭断、局部缺口、细微中断等问题。系统沿着测量点展开局部观察,并不只是为了“看到某个点”,而是为了进一步感知与该点相关的结构连续性是否还成立。
第三类,是局部面积、残余与异常聚集。
这类测量更接近多镭、残胶、局部残余区域或异常填充等问题。它们往往不表现为单点灰度异常,而表现为某种局部区域的宽度扩张、面积残留或异常堆积。
因此,这一篇真正应该让读者看清的是:这套系统里的“测量”从来都不是泛泛的,它始终对应某类明确的局部几何量或灰度量,而后续缺陷判定也正是建立在这些量之上。
三、为什么系统不是沿整张图测,而是沿测量点逐点展开
这套系统最有特色的地方之一,就是测量不是对整张图做盲目的密集搜索,而是沿着已经落位的测量集逐点展开。
这一点非常重要。因为一旦测量点已经通过配准进入了正确位置,系统就不再需要在整张图里到处“猜”哪里值得看,而是可以直接把注意力集中在那些本来就应该存在结构的位置上。也就是说,后续测量不是在全图漫扫,而是在一个已经被模板和配准缩小过、组织过的局部空间里进行。
这样做的好处有两个。
第一,它让系统对细微缺陷更敏感。
因为测量不是在无上下文的位图区域里比较亮暗,而是在“本来应该有结构”的位置上比较结构偏差。这样一来,非常小的缺口、局部中断、极细的异常区域,都会更容易被稳定地显现出来。
第二,它让系统对无关噪声更不敏感。
因为系统并没有把整张图都当成等价检测对象,而是把注意力限制在已经落位的局部结构上。很多来自背景、局部污染、边缘偶然波动的干扰,根本不会轻易进入最终判定链条。
所以,这套系统的检测并不是“看整张图哪里不对”,而更接近于:
沿着一组已经落位的结构点,逐点展开局部测量,再把这些局部测量组织成最终缺陷。
四、不同缺陷类型为什么能够被统一纳入同一套测量框架
从表面上看,这套系统里最终面对的缺陷类型很多:镭断、色异常、多镭、局部失配、码数量异常等等。它们的视觉表现也并不一样,似乎应该对应不同的算法模块。
但如果从更深一层的机制看,这些缺陷并不是若干套彼此孤立的逻辑,而是被统一纳入了同一条主线之中:
- 测量集已经落位;
- 局部邻域被展开;
- 某种局部几何量或灰度量被测出;
- 点级异常被记录;
- 再通过邻域关系聚并为缺陷区域或缺陷类型。
也就是说,不同缺陷类型虽然“长得不一样”,但它们在系统里进入检测链条的方式其实非常相似:都先表现为某些测量点上的局部异常,再逐步从点级异常上升为可输出的缺陷结果。
这一点很关键。因为它说明这套系统并不是把每一类缺陷都单独写成一套完全不同的流程,而是在一个统一的测量框架上,允许不同类型的局部量去触发不同的异常解释。正因为如此,系统才没有退化成“缺陷类型越多,逻辑越碎”的规则堆叠,而是仍然保持了一条比较清楚的技术主线。
五、从点级异常到最终缺陷:系统是怎么聚并和判定的
测量点上的局部异常并不会立刻等价于最终缺陷。因为在真实现场里,孤立的异常点可能来自局部波动、偶然噪声或者边界不稳定。如果系统只要某一个点异常就直接判 NG,那么误报会非常高。
因此,这套系统真正的判定过程并不是“点异常 = 缺陷”,而是更接近下面这条链:
- 某些测量点先表现出局部异常;
- 系统再观察这些异常点在邻域内是否形成足够稳定、足够密集的异常集合;
- 当这种集合达到一定结构条件后,才进一步形成缺陷区域、缺陷类型和最终输出。
这一步的意义非常大。因为它解释了为什么系统既能抓住很细微的缺陷,又不会因为少数孤立噪声点就轻易乱报。换句话说,点级测量负责“发现异常苗头”,而后续聚并负责“把异常苗头解释成真正可输出的缺陷”。
也正是在这一层,系统才真正完成了从“局部测量”到“工业输出”的转换。
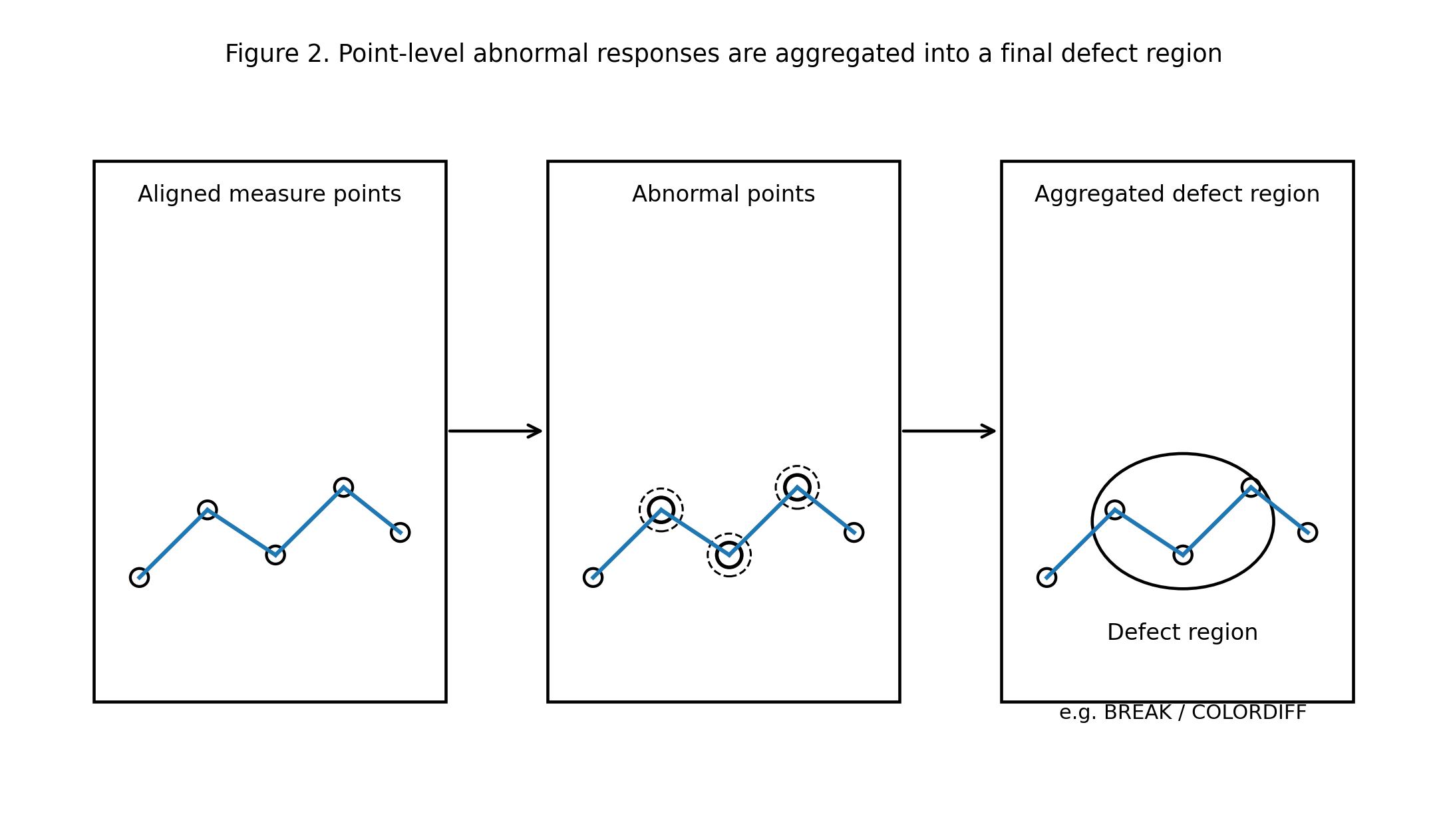
图 2:从点级异常到最终缺陷。系统不是看到单个异常点就立刻判 NG,而是通过邻域聚并,将局部异常点组织成最终可输出的缺陷区域。
六、为什么这套系统能测到非常细微的缺陷
如果只看最终结果,很多人会把系统能抓到细微缺陷归功于某个特别强的分类器、某个很高深的特征,或者某种特别神秘的阈值策略。但对这套系统来说,更根本的原因并不在那里。
它之所以能测到非常细微的缺陷,首先是因为模板结构已经通过配准真正落入了实测图像;其次是因为后续测量并不是在整张图里盲扫,而是沿着这些已经落位的结构点逐点展开。也就是说,系统始终是在“应该有结构的地方”测偏差,而不是在无差别地扫整张图。
为了让这一点更直观,不妨把“模板已经真正落位”和“细微缺陷如何显现”放在同一张图里看。左侧给出的是中轴线配准后的现场效果图:绿色线条并不是人工标注,而是由现场软件依据模板结构在实测图像上自动生成的骨架,也就是 xml 中 skeleton 在图像中的实际落位结果。它的意义不只是“看起来对齐了”,而是说明后续测量所依赖的结构关系已经真正进入了实测对象。
右侧则给出几类真实产线样本中的局部缺陷效果图,包括镭断和多镭等典型情形。图中保留的是与缺陷相关的局部区域,红色方框标示系统检测到的异常位置。这样并排来看,这套系统之所以能测到非常细微的缺陷,原因就会更清楚:它不是先在整张图里盲目寻找异常,而是在模板已经落位、骨架关系已经建立之后,沿着这些结构去感知局部偏差。正因为如此,一些在位图层面容易淹没在噪声、亮度波动或局部不均匀中的细微缺陷,才会变成可测的结构异常。

图 3:左侧为配准后的中轴线覆盖效果,右侧为真实产线样本中的局部缺陷检测结果。左:绿色中轴线为配准后叠加到实测图像中的结构模板;右:红色方框标示系统检测到的局部缺陷。
正因为如此,它才能够对一些极其细小但真实的结构异常保持敏感。例如,某个局部点缺失、一段笔画中间断掉一个很小的方块,或者某个局部邻域里出现轻微但真实的异常膨胀。如果只在原始位图层面去看,这些现象很容易与噪声、局部亮度波动或成像不均匀混在一起;但一旦放到已经落位的骨架和测量关系上,它们就会变成更可解释、也更可测的局部结构偏差。
七、为什么这套测量层本质上仍然是结构化测量,而不是简单规则堆砌
从表面上看,这套系统当然有不少参数、阈值和局部判别逻辑。于是很容易有人觉得,它最终不过是一套调参很多的规则系统。这个印象并不奇怪,因为如果只看配置文件里的参数名,而不去看它们依附在哪一层机制上,确实会觉得“规则很多”。
但问题的关键不在于“有没有参数”,而在于:这些参数是不是悬空存在的。
为了说明这一点,不妨先看一小段经过简化后的参数组织方式:
[Path]
XmlPath=.\lab_config\AM\laserCarving_TCharge.xml
[Param]
ThresholdBlockSize=...
contAreaMin=...
contAreaMax=...
NeighbourSize=...
NgPointNumThres=...
CharPointNumThres=...
DiffThres=...
MatchingThres=...
IterCount=...
MaxPointDist=...
DistYThres=...
[Defect]
detectType=11
LightThres=...
DarkThres=...
GlobalColorThres=...
GumThres=...
DiaThres=...
ResidualAreaThres=...
ZeroDiaRate=...
detNormThres=...
如果只看这些名字,确实会觉得参数不少。但稍微往下看一层,就会发现,它们并不是杂乱堆在一起的,而是分属不同层级。
第一层参数,服务于模板入口与对象形成。
最上面的 XmlPath 并不是一个普通路径项,它实际上把当前这份 ini 直接连到了对应国别或产品面的 xml 模板上。也就是说,这套系统一开始就不是“先有一堆阈值,再想办法去适配对象”,而是先由 xml 给出字符骨架、全局几何锚点、block 组织和模板入口,ini 再去调节这一整条检测链如何工作。
第二层参数,服务于前端提取与 block 形成。
例如 ThresholdBlockSize、contAreaMin、contAreaMax、SquareKernelSize、blurringKernelSize、KernelSizeForCont,控制的是局部二值化、轮廓筛选、膨胀与降噪等前处理过程。它们回答的不是“最后判什么 defect”,而是“哪些区域有资格进入后续检测链”。
这里面 CharPointNumThres 又尤其重要。它并不是一个随意的点数限制,而是字符区域的有效点阈值:只有当字符区域中的有效点数量达到这一阈值,系统才认为该字符区域正常,并把它计入对应 block。也就是说,这个参数控制的不是最后怎么判缺陷,而是某个局部结构是否足够成立、足够完整,能够进入后续几何关系之中。
第三层参数,服务于配准与结构落位。
例如 MatchingThres、IterCount、MaxPointDist、DistYThres、NeighbourSize 等量,控制的是模板匹配是否成立、点集对应范围有多宽、迭代配准做多少轮,以及局部测量尺度取多大。这里特别值得注意的是:这些参数并不直接决定某个缺陷是否成立,而是首先决定模板、block 和测量点能否被稳定地带到合理位置。换句话说,它们服务的是“结构如何落位”,而不是“结果如何直接给出”。
第四层参数,直接对应局部测量对象本身。
例如 LightThres、DarkThres、GlobalColorThres、DiaThres、ResidualAreaThres、ZeroDiaRate、detNormThres,分别对应局部灰度与对比关系、整体色异常、局部宽度或直径类量、残余区域以及整体失配程度等辅助量。也就是说,这些参数并不是拍脑袋写出来的,而是挂在“系统到底在测什么”这一层上的。
这里的 detectType 也不能被简单看成一个普通开关。它实际上决定了当前这份配置到底激活哪几类缺陷通道。例如 detectType=11,按位展开之后对应的是 1 + 2 + 8,也就是当前场景下主要启用了 镭断、色异常和多雕 这几类检测。这说明系统并不是在所有场景下把所有缺陷一股脑都打开,而是会针对具体产品面、具体图档和具体业务场景,有选择地组织当前真正需要的测量任务。
第五层参数,控制的是点级异常如何上升为最终缺陷。
例如 NgPointNumThres,以及更完整配置中出现的 BreakPointNumThres、ColorDiffPointNumThres、LargeDiaPointNumThres、convergRadius 一类量,本质上都不是在定义单点异常本身,而是在定义:异常点在邻域内达到什么规模、什么密度之后,才足以形成可输出的缺陷。这也解释了为什么系统不会因为某一个孤立点的轻微异常就立刻乱报。
还有一类参数,控制的是局部展开方式与局部测量环境。
例如 DiffThres、availNeighbourRate4Break、availNeighbourRate4ColorDiff、binaryzationType、bgRate 这类量,决定的是局部邻域怎样形成、哪些局部信息被视为有效、背景与结构如何区分。这里的 DiffThres 也并不是一个普通差分阈值,而是和是否通过投影来做阈值分割相关,尤其在 SN 码区域 上更有效。这说明系统的某些参数并不是在“直接判 defect”,而是在决定局部测量该以什么方式展开。
换句话说,参数在这里只是控制量,而不是问题本体。问题本体始终是:模板如何落位,测量点如何展开,局部异常如何被解释。
所以,从更本质的角度看,这一层并不是简单规则堆砌,而是一种建立在模板、配准、测量点和局部邻域之上的结构化测量系统。参数当然存在,但它们不是主干;主干始终是:先把结构关系建立起来,再让参数和规则落到已经成立的结构之上。
也正因为如此,这套系统虽然有不少可调参数,但它并没有退化成“规则越写越多、阈值越调越碎”的经验拼装。相反,它的参数之所以能够工作,恰恰是因为前面的模板组织、两层配准和测量点落位,已经把问题约束在了一个足够稳定的结构框架里。
八、这一篇的结尾:从“如何测”走向“如何输出”
到这里其实可以看清:这套系统里的缺陷检测,并不是直接从图像里“扫出来”的,而是沿着已经落位的测量集被逐点测量、再逐步聚并出来的。
因此,这一篇最重要的结论可以压缩成一句话:
缺陷不是直接从整张图里找出来的,而是沿着已经落位的测量集被测出来的。
这也意味着,系统真正的难点并不只是“有没有一个判定规则”,而在于:模板、配准、测量点、局部邻域和缺陷输出之间,能否被组织成一条连贯的技术主线。
下一讲,我会继续沿着这里往下写:这些已经形成的缺陷结果,最终是如何进入并适应产线节拍、并行处理、多线程组织和工程实施流程的。