第三讲:为什么曲面 Pattern 缺陷检测系统能跨产品复用——一份 XML 里的模板、几何组织、拓扑与运行分支
Why Curved-Surface Pattern Inspection Systems Can Be Reused Across Products: Templates, Geometric Organization, Topology, and Runtime Branching in One XML File
English Abstract
This article explains why the inspection system can be reused across different products, regions, and production lines with minimal changes to the core DLL. The key lies not merely in universally adaptable code, but in an external XML-based geometric description layer that organizes structural templates, minimal registration units, register/measure point roles, global geometric objects, block-level organization, topology-aware priors, directional tolerance, and runtime product branches in a unified way. From this perspective, the XML file is not a passive configuration file, but an explicit structural description of how the system understands, organizes, and activates its detection objects.
如果只从外部看,很多人会以为这套系统之所以能在不同国别、不同产品甚至不同产线之间复用,主要靠的是“代码写得通用”。但真正做过这套系统的人会知道,事情并不是这样。它真正的关键,不在于不断修改核心 DLL 去适配变化,而在于把大量会变化的东西,提前组织进了一套外部几何模板文件里。
对这套系统来说,xml 不是附属配置,而是模板、几何组织、拓扑、容错与运行分支逻辑的共同载体。也正因为如此,很多产品切换时,真正需要改动的并不是核心代码,而主要是图档、xml 和 ini 这一层。换句话说,这套系统真正可复用的前提,不是“什么都写死在程序里”,而是把变化压缩进一套结构化、可替换、可维护的模板描述层。
为了避免一上来就陷入字段细节,先看这份 xml 的整体结构。只有先看到它的层次,后面关于模板、几何锚点、block 和产品入口的讨论才不会显得零散。
<entity>
<character>
<skeleton name="jt" size="..." genus="0">
<p x="..." y="..." t="1" />
<p x="..." y="..." t="0" />
<!-- ... -->
</skeleton>
<skeleton name="logo" size="..." genus="1">
<p x="..." y="..." />
<!-- ... -->
</skeleton>
<skeleton name="CCAI19LP" size="..." genus="1">
<p x="..." y="..." />
<!-- ... -->
</skeleton>
<!-- ... -->
</character>
<globalGeo size="...">
<Geo name="sn" size="12" extValue="1186" smode="0" repres="0" type="1">
<p x="..." y="..." prio="1" />
<!-- ... -->
</Geo>
<Geo name="logo" size="3" extValue="1111" smode="0" repres="1" type="1">
<p x="..." y="..." prio="1" />
<!-- ... -->
</Geo>
<!-- ... -->
</globalGeo>
<blockSet size="...">
<block extValue="0" prio="1" type="1" />
<block extValue="0" prio="1" type="2" />
<!-- ... -->
</blockSet>
<eraseSet size="...">
<erase ... />
</eraseSet>
<templPathSet size="2">
<product templatePath="tw1.bmp" type="1" rows="..." cols="..." xOffset="0" yOffset="0">
<holder relocation="1" relocRadius="100" xRange="400" yRange="600" />
</product>
<product templatePath="tw2.bmp" type="2" rows="..." cols="..." xOffset="0" yOffset="0">
<holder relocation="1" relocRadius="100" xRange="400" yRange="600" />
</product>
</templPathSet>
<defectParam>
<param baseIndex="15" infimum="50" supermum="150" type="skewing"/>
</defectParam>
</entity>
上面这段代码只保留了 xml 的主干结构。实际文件中,character 下会列出项目里出现的各类字符或局部图样 block 的结构模板,globalGeo 下则保存对应的全局几何锚点。这里省略了大量具体点坐标,只保留其组织方式,是为了更直观地展示这份模板文件背后的几何逻辑。
如果先不陷入字段细节,而只抓住这份 xml 的主干结构,那么它做的事情其实非常明确:一方面保存字符或局部图样的结构模板,另一方面保存全局几何锚点、block 组织方式、局部擦除规则以及产品模板入口。也就是说,它并不是单纯存一张参考图,而是在系统层面描述:这个产品上有哪些可检测对象,它们大致位于哪里,哪些局部结构要被拿来做注册与测量,哪些区域需要额外容错,以及不同产品面分别对应哪一套模板入口。
从这个角度看,这份 xml 更接近一份产品几何描述文件,而不是普通意义上的配置文件。其内部层次也很清楚:
character下组织的是多个skeleton,也就是字符或图样的局部结构模板;globalGeo下保存的是命名的全局几何点集,用来提供更上层的定位锚点;blockSet定义了当前产品实际参与检测的block序列;eraseSet给出局部擦除与屏蔽规则;templPathSet负责把具体产品模板图接入系统。
更进一步,holder、repres、t 和 defectParam 这些字段还说明,这套系统保存的并不只是“点和路径”,而是点的角色、表示方式、重定位策略和某些更高层的检测语义。
还有一层此前很容易被低估,但实际上非常关键的关系,就是 Geo、block 与 type 之间的对应。
如果只把 globalGeo 看成“全局锚点集合”,那仍然说浅了。更准确地说,globalGeo 在这套系统里承担的是 block 的几何组织层:它先把产品上的局部对象组织成一组精确几何单元,再由这些几何单元展开成后续运行时真正参与检测的 block。与此同时,type 又把 templPathSet 中的模板图入口、globalGeo 中的几何对象集合以及 blockSet 中的运行单元序列绑成同一条产品分支。
也就是说,这份 XML 并不是“先有模板图,再有若干 block”这么简单,而是在模板层、几何层和运行层之间,已经预先建立了严格的组织关系。
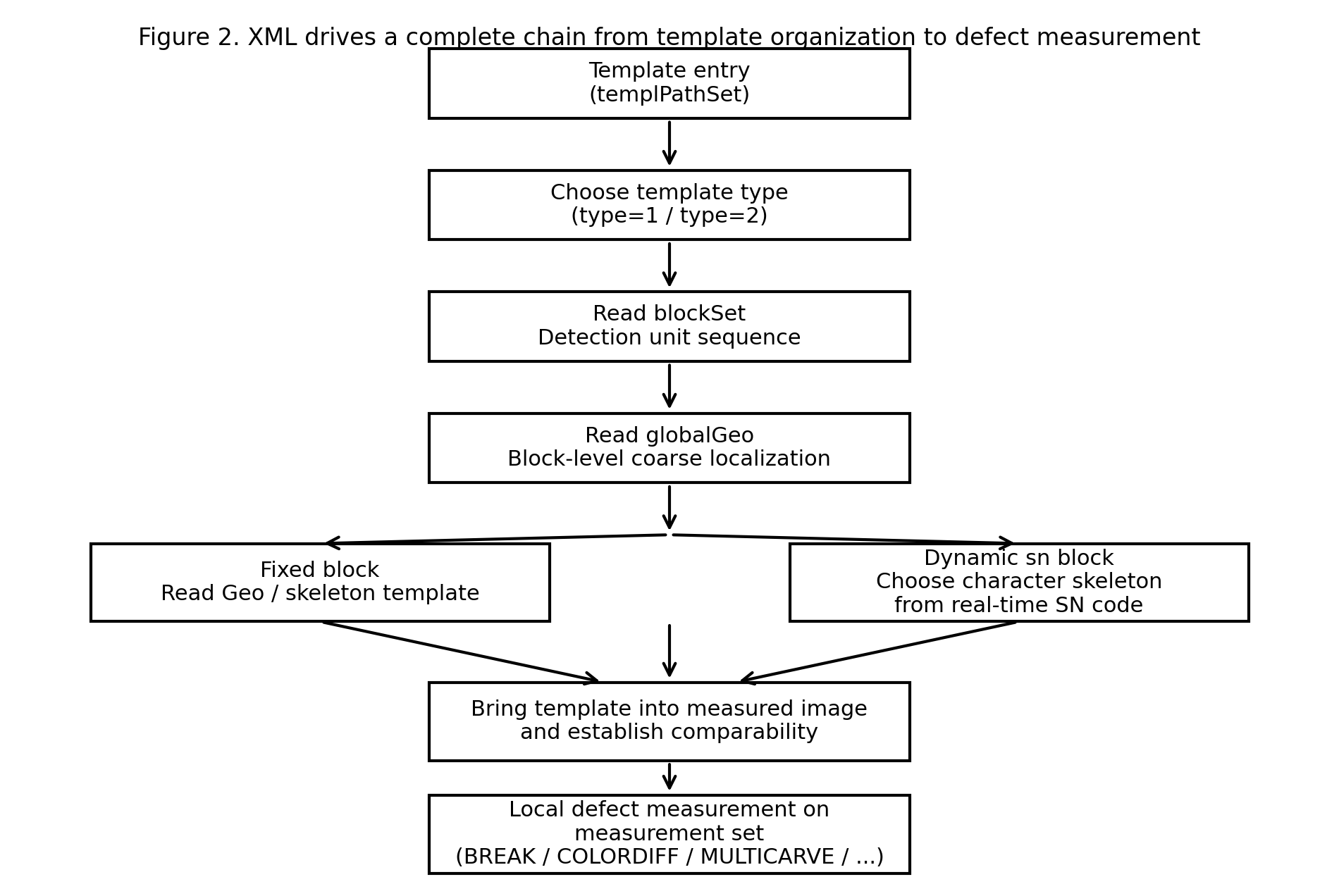
图 1: 这份 xml 真正驱动的不是简单模板匹配,而是从模板组织、几何定位到局部缺陷测量的一整条检测链。
一、character:这里存的不是“字”,而是字符/图样的结构模板
很多人第一次看到 xml 里的 character,会下意识把它理解成“文本内容”。其实不是。这里真正保存的,并不是字符语义,而是字符或局部图样的结构表达。在项目里,像 jt、logo、CCAI19LP、E 这样不同名字的 skeleton,下面都挂着一组 p(x,y) 点,它们共同构成了该对象的局部模板。
最常见的情况下,这类点集就是 medial axis,也就是中轴/骨架点集;但更准确地说,它们是一类可用于注册与测量的结构点模板。这里的重点并不在于“骨架”这个词本身,而在于:一旦模板保存的不是图片,而是结构点集,后面的系统行为就会完全不同。
- 图片只能拿来“比”;
- 而点集结构既可以用来配准,也可以用来测量,还可以继续挂接拓扑信息、点角色和表示方式等更深一层的几何语义。
也就是说,从这一层开始,这套系统就已经不是在做简单模板匹配,而是在做结构模板驱动的检测。
二、骨架点并不都一样:有些点用于注册,有些点用于测量
更完整的 XML 里,骨架点甚至不只是“属于某个 skeleton”,而是还带有 t 这样的角色字段。实现代码里,t=1 的点会进入注册集,t=0 的点会进入测量集。也就是说,注册集与测量集并不是事后在程序里随意拆分出来的,而是在模板描述层就已经被明确编码了进去。
下面这段代码已经把这件事说得很清楚:
x = atoi(p_p->Attribute("x"));
y = atoi(p_p->Attribute("y"));
t = atoi(p_p->Attribute("t")); // topological / role property
if (1 == t)
{
s.ps4regist[s.num4regist][0] = x;
s.ps4regist[s.num4regist][1] = y;
s.num4regist++;
}
else if (0 == t)
{
s.ps4measure[s.num4measure][0] = x;
s.ps4measure[s.num4measure][1] = y;
s.num4measure++;
}
这件事非常关键。因为它说明 XML 保存的并不只是几何点的位置,还在更深一层上保存了这些点在系统中的功能角色:哪些点更适合承担定位约束,哪些点更适合承接后续测量。换句话说,这套系统并不是先有一堆骨架点,再临时决定怎么用它们,而是在模板层就已经开始区分“为配准服务的点”和“为检测服务的点”。
这也意味着,后面第四篇里要讲的注册集与测量集分工,并不是某种运行时临时策略,而在 XML 这一层就已经埋下了结构基础。
三、skeleton 不只是“字符骨架”,而是配准的最小结构单元
如果只从字段名字看,skeleton 很容易被理解成“某个字符的骨架模板”。但从更真实的工程意义上说,它并不只是字符骨架,而更接近这套系统里配准的最小结构单元。这件事非常重要,因为最小单元到底取多小,并不是无关紧要的实现细节,而会直接影响配准稳定性、漏检风险和过杀风险。
在一些场景下,一个字符会单独作为一个 skeleton;而在另一些场景下,多个字符甚至一整个局部图样会被合并成一个 skeleton。两种做法各有优势。
单字符 skeleton 的优点是定位更细、更灵敏,局部异常更容易暴露出来;但它的缺点也很明显:对某些结构过于简单、拓扑信息过弱的字符,非刚性配准的自由度可能会把局部缺失“吸收”掉。比如字符 "1",即使原图中已经少掉一段,模板仍然可能在整体上配准成功,从而带来现场漏检。
相比之下,多个字符合并而成的 skeleton 会在配准阶段提供更强的结构约束。因为这时系统面对的不再是一个局部过于简单的对象,而是一个包含更多相对位置关系、更多几何冗余、也更不容易被自由形变悄悄解释掉的整体结构。换句话说,单字符 skeleton 更强调灵敏度,而多字符 skeleton 更强调鲁棒性。
这里面最核心的,其实是拓扑和结构复杂度对配准稳定性的影响。像 "B"、"6" 这类具有环柄、回绕或更强结构闭合感的对象,在非刚性配准中通常会比 "1" 这类细长、单一、低复杂度对象更稳定。原因并不神秘:结构越复杂,模板中各局部之间的相互制约就越强,能够被自由形变吸收掉的空间就越小。对于汉字或不规则图形,如果单个局部本身过于脆弱,也可以通过合并多个字符或多个局部结构来提升配准稳定性。
从这个角度看,skeleton 的意义就不只是“骨架点集”,而是系统在模板层面对“最小配准单元”所做的一种结构设计。它既关系到模板如何表达对象,也关系到配准如何在灵敏度与鲁棒性之间取得平衡。
四、genus:模板不仅有几何,还有拓扑
这份 xml 里很多 skeleton 都带了 genus。如果不解释,这个字段会显得很怪;但它其实非常有意思。这里的 genus 指的是亏格,也就是对象从骨架角度看具有多少环柄或孔洞结构。换句话说,这套系统不是把字符模板只看成一堆点,而是进一步把它们看成带有拓扑类别的结构对象。
这一点很值得注意。它说明这套系统并不是在“尽量把工程写简单”,而是在真正有价值的地方引入了很少但很有效的数学信息。一个字符或者图样,仅靠局部几何位置,有时会因为形变、缺损、提取误差而变得不够稳;但一旦把亏格也带进来,模板匹配和结构选择就多了一层更稳的先验。它未必总是决定性的,但在复杂现场里,往往足以提高成功率。
更进一步说,genus 的意义并不只是“给对象贴一个拓扑标签”,而是和前面谈到的最小配准单元选择互相呼应:结构越复杂、拓扑越强,非刚性配准越不容易把真实缺失解释成“正常形变”;而对那些拓扑过弱的对象,就需要通过合并多个字符或局部图样来补强约束。也就是说,拓扑信息不是孤立存在的字段,它实际上参与了系统如何平衡配准鲁棒性与缺陷敏感性的思路。
五、globalGeo:这不只是全局锚点层,而是 block 的几何组织层
如果说 character / skeleton 负责局部结构模板,那么 globalGeo 负责的就不是简单意义上的“补充定位信息”,而是更上层的 block 几何组织。
这一点在完整 XML 里已经非常清楚。像 sn、logo、A2190、CCAI19LP、jt 这样的 Geo,表面上看只是命名点集;但从系统运行的角度看,它们真正提供的是:某个局部检测对象在产品面上的几何代表信息。在当前实现里,这类几何信息最典型的形式就是中心点集合,它首先服务于较粗层级上的点集配准,然后再把后续的局部模板、注册集和测量集带入实测图像。
也就是说,globalGeo 不是泛泛的“锚点层”,而是介于模板层与运行层之间的 几何组织层:它先告诉系统“产品上有哪些局部对象、它们大致在哪里、如何以中心点集合的方式被几何表示”,然后这些对象才进一步进入后续的 block 检测链。
这里还有一个很容易被忽略、但其实非常关键的事实:Geo 和 block 并不是彼此独立的两套描述。在很多配置里,普通 Geo 往往对应一个局部检测单元;而像 sn 这种槽位型对象,则会按字符位数进一步展开成多个 block。例如,在某些配置中,globalGeo 里除了 sn 之外还有若干普通 Geo,而 sn 自身包含 12 个字符槽位点;于是,前面的普通 Geo 各自对应一个 block,sn 再按 12 个字符位展开成 12 个 block,最后与 blockSet 的总数严格对应。
这件事非常重要。因为它说明系统并不是先把检测对象机械切成若干小块,再倒过来补一些几何信息;恰恰相反,它是先在 globalGeo 这一层完成对象的几何组织,再把这些几何对象投影成运行层真正参与检测的 block 单元。换句话说,Geo 给出的不是抽象参考点,而是 block 如何从产品几何中被组织出来 的依据。
从这个角度看,globalGeo 的意义就远不只是“粗定位用的点集”。它实际上承担的是:把产品上的局部对象组织成一组可配准、可展开、可进入检测链的几何单元。
六、repres 与 holder:XML 里不仅有模板,还有表示方式与重定位策略
这份 XML 进一步有意思的地方,在于它并不只是存了骨架点和锚点,还存了这些对象在系统里“该如何被看待”。
例如,代码里对应的表示方式有这样一个枚举:
typedef enum REPRES
{
MEDIALAXIS, POINTTOPO
} Represent;
这说明模板对象至少支持两种不同的结构表述:一种更接近中轴骨架,另一种则更接近点拓扑式表达。换句话说,系统并不是用单一方式理解所有对象,而是允许不同对象以不同结构语义进入检测链。
另一方面,templPathSet 下面的 holder 也不只是“顺手挂了个子节点”。从对应结构体可以看出,它实际上是产品级整体模板的重定位与约束信息:
typedef struct WholeTempl
{
char path[MAX_PATH];
int xOffset;
int yOffset;
int xRange;
int yRange;
bool avail;
int relocation;
int relocRadius;
Mat mat;
} Holder;
这意味着产品模板入口除了路径本身,还保存了偏移范围、搜索范围、是否可用、是否重定位以及重定位半径等信息。也就是说,系统并不是简单读入一张 bmp 然后“拿来比一比”,而是在产品级整体模板这一层就已经准备了后续定位所需的整体上下文。
从这个角度看,XML 保存的已经不是“模板文件路径 + 点坐标”这么简单,而是一整套关于对象如何表示、如何进入图像、如何被重定位的描述。
七、blockSet:系统真正运行的检测单元,是从几何对象层展开出来的
这份 XML 里还有一层特别关键,就是 blockSet。如果只看字段名,最容易把它理解成“当前产品有哪些 block 的清单”;但从更真实的系统意义上说,它并不是独立存在的一张列表,而是由前面的几何组织层进一步展开出来的 运行单元序列。
也就是说,blockSet 不是凭空定义“这一页有多少个检测块”,而是在 globalGeo 已经把局部对象组织出来之后,再把这些对象转成运行时真正参与配准、测量和结果输出的 block。普通 Geo 往往各自承接一个 block;而像 sn 这样包含多个字符槽位的对象,则会按字符位数拆成多个 block。这样一来,blockSet 的大小就不是随意决定的,而是和 globalGeo 中的对象组织严格相关。
这一点很能说明这套系统的层次感。它不是“整张图像里有什么就扫什么”,而是先在几何层上明确有哪些对象值得作为检测单元,再让这些对象进入 block 层成为真正的运行任务。于是,block 的意义就不只是代码实现上的一个局部小块,而是:
- 它承接了模板对象;
- 承接了几何粗配准;
- 承接了后续的局部模板落位;
- 也承接了最终的缺陷测量与结果输出。
这也解释了为什么系统天然适合并行。因为系统真正工作的,不是“整张图像里到底发生了什么”,而是“这些 block 中,每一个是否在自己的几何位置上以正确方式出现了”。一旦对象已经在几何层上被切分成这样的检测单元,后面的两层配准、局部测量和线程任务拆分才都会变得自然。
八、extValue:容错不是模糊地放大,而是方向化编码
这份 xml 里还有一个很值得注意的设计,就是 extValue。它并不是简单地给 block 增加一个统一 margin,而是把扩展量编码成了四个方向上的显式规则:左、右、上、下分别由不同位上的数字决定,再统一乘以扩展倍数。这样做的意义很直接:前级提取出来的 block 在现场往往存在误差,而这种误差通常又不是均匀的,不同方向上的偏移风险并不相同。把容错写成方向化的几何规则之后,系统就不必把这类补偿零散地留给后续代码去处理,而是可以在模板描述层面提前吸收一部分定位误差。
这就是我说这份 xml 很有“系统之美”的原因。它不是靠一个神秘参数去赌运气,而是把容错做成了几何上可解释、工程上可维护的规则。这样一来,成功率的提升不是来自运气,而是来自设计。
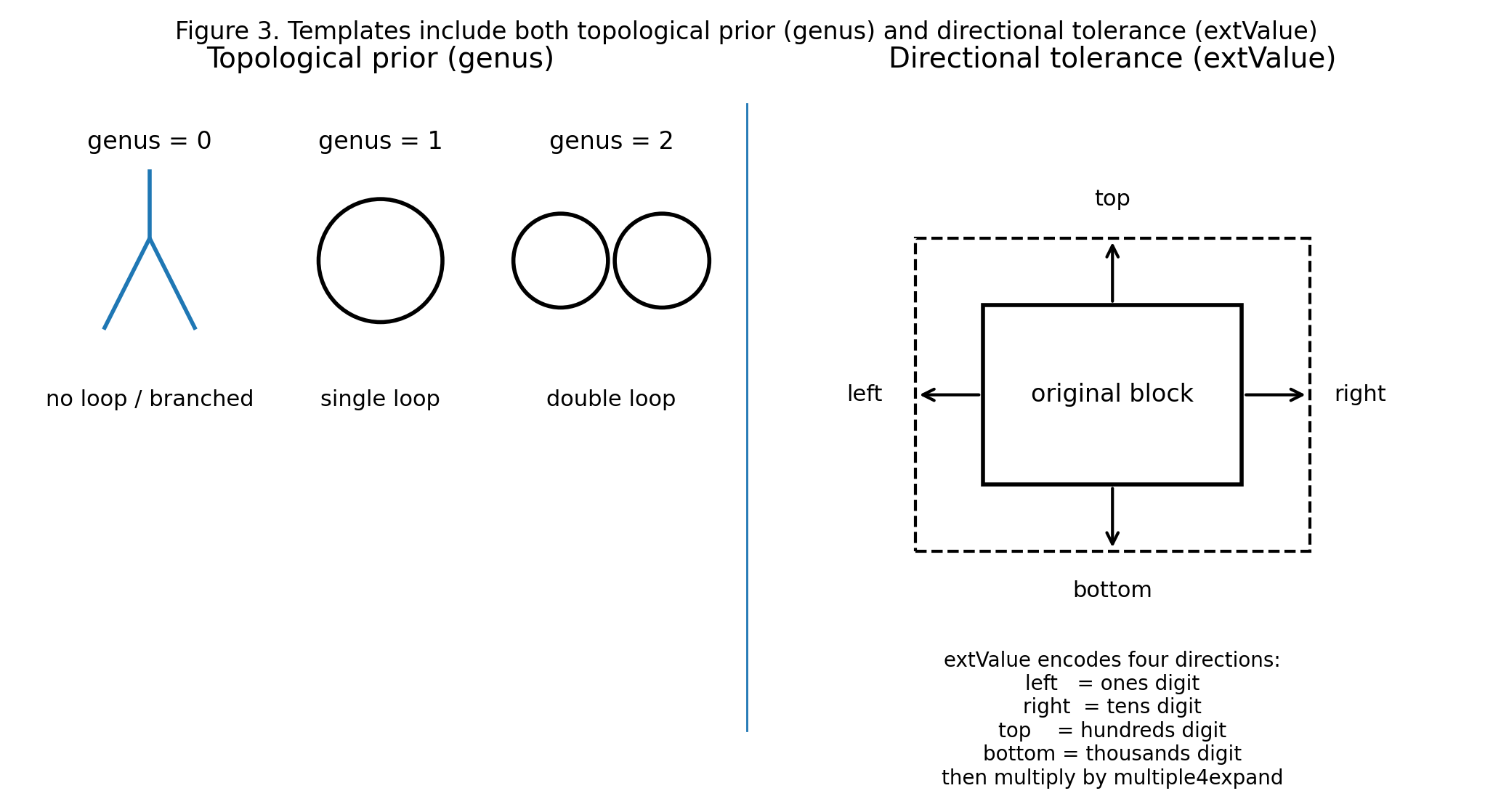
图 2: 模板文件中不仅保存几何点集,还通过 genus 与 extValue 分别引入了拓扑先验和方向性容错。
九、eraseSet、templPathSet、type 与 defectParam:模板不是死的,运行分支也不是单入口
eraseSet 和 templPathSet 这两层,看起来像工程尾巴,其实很能体现这套系统的成熟度。前者说明模板不是死存储,而是允许做局部擦除和结构性屏蔽;后者则说明系统并不是只面对单一模板图,而是可以在运行时根据当前对象所对应的产品分支,进入不同的模板图入口。
这一点在完整 XML 里尤其清楚。templPathSet 中的不同 product 不只是挂着不同的 bmp 路径,它们还带有 type、angle、rows、cols、xOffset、yOffset 以及 holder 等信息。这里最关键的,并不是“有两张模板图”,而是:不同模板入口会进一步对应不同的几何对象集合和不同的 block 序列。
也就是说,type 在这里不是普通分类字段,而是把几层东西绑成同一条运行分支:
templPathSet / product@type决定当前进入哪一个模板图入口;globalGeo / Geo@type决定当前启用哪一组几何组织对象;blockSet / block@type决定当前激活哪一组运行检测单元。
这件事非常重要。因为它说明系统并不是“同一张模板图上换一些参数”那么简单,而是在运行时已经能够根据当前产品面别或图档分支,进入不同的模板入口,并随之切换不同的几何组织与 block 集合。对于蓝牙耳机充电盒这类对象,这一点尤其有意义:正面和反面都可能存在镭雕,而同一条产线上的相机往往需要分两次拍摄。于是,算法面对的就不再是“固定一张模板图”,而是必须根据当前拍摄对象所属的面别,进入不同的 product 分支,并进一步带出不同的 Geo 组织和不同的 block 检测链。
与此同时,angle 这样的属性还说明系统在产品级入口层就已经考虑了旋转适配问题。也就是说,模板图入口并不是假定 ROI 永远是严格水平的矩形,而是允许在一定旋转条件下进入后续定位和检测链。这并不意味着系统对任意姿态完全不敏感,而是说明在产品级模板入口这一层,已经开始吸收实际 CCD 拍摄中不可避免的角度偏差。
而 holder 进一步说明,这里保存的也不只是路径本身,还包括整体模板的重定位与范围约束信息。换句话说,templPathSet 不是在“给后面找一张参考图”,而是在定义:当前产品分支应该从哪一个整体模板入口开始、以什么范围与什么约束进入后续检测链。
完整 XML 里进一步出现的 defectParam,则更说明这份文件不只是“模板清单”,而是已经开始承接一部分更上层的检测语义。比如 type="skewing" 这样的字段,就已经在告诉系统:除了局部结构模板和定位锚点之外,还有某些整体层面的缺陷参数也会在这里被外部描述。
这几层叠加在一起,就使得 XML 不再只是“模板文件”,而更接近一份真正的 产品几何描述文件:它既告诉系统“你要看什么”,也告诉系统“你不用看什么”;既告诉系统“当前应从哪一个模板入口进入”,也告诉系统“这一入口下有哪些几何对象和哪些 block 应该被激活”;甚至还开始承接某些更高层的检测参数。
十、所以,这份 XML 真正保存的,是系统对检测对象的结构理解
如果一定要用一句话概括这份 XML,我不会说它是“检测配置文件”,也不会说它只是“模板文件”。更准确的说法是:
它是一份把字符库、最小配准单元、注册/测量点角色、block 的几何组织、拓扑先验、方向容错以及产品模板运行分支统一到一起的几何描述文件。
这句话听起来有点长,但它比“配置文件”接近真实得多。因为真正支撑这套系统跨国别、跨产品、跨产线复用的,恰恰不是不断改代码,而是这种把变化压缩进模板描述层、几何组织层和运行分支层的能力。
从这份 XML 可以看出,这套系统并没有把关键判断零散地埋在代码里,而是把检测对象的组织方式、配准与测量的角色分工,以及若干灵敏度—鲁棒性平衡,尽量外化到了同一套模板描述层中。
下一讲将进入这套系统最核心的几何机制:两次配准如何工作,注册集与测量集为什么要同步推进,以及配准为何只是后续缺陷测量的几何基础。