从 RGB-D 标定到稀疏几何查询
A low-level 3D vision scheme for calibration, sparse cross-sensor mapping, and lightweight 3D recovery
冯玮(Wei Feng)
这篇文章整理的是我在 2019–2020 年前后做过的一套 RGB-D 底层视觉方案。它不是一个已经被完整整理成论文或正式产品文档的成果;它更像一个在很短时间内做出来、后来没有继续展开,但核心问题其实写对了的原型。
它真正有价值的地方,不在于“做了一个 RGB-D 标定模块”,而在于它把跨传感器点对应问题,从整幅图像的通用稠密映射,改写成了一个面向少量关键点的稀疏几何查询问题。
核心思想
给定 RGB 图上的一个关键点,不去生成整幅 RGB–Depth 映射场,而是先构造该点在三维中的视线,再在受限深度区间内生成候选三维点,把每个候选点投到深度相机,并用深度一致性来判断哪个假设成立。
English Abstract
This article reconstructs a low-level RGB-D vision scheme I built around 2019–2020 for calibration, cross-sensor point mapping, and lightweight 3D recovery. The key insight was that the practical task was not dense RGB–depth alignment over the entire image, but sparse mapping of a small number of RGB feature points into the depth image and then into 3D. Instead of relying on the vendor API for full-frame remapping, the scheme reformulated the problem as a task-specific geometric query: given one RGB feature point, generate a 3D viewing ray, sample along a constrained depth interval, project each 3D hypothesis into the depth camera, and validate it by depth consistency.
这篇文章整理的是我在 2019–2020 年前后做过的一套 RGB-D 底层视觉方案。严格说,它不是一个已经被完整整理成论文或正式产品文档的成果;它更像一个在很短时间内做出来、后来没有继续展开,但核心问题其实写对了的原型。
如果只从功能描述上看,它不过是“RGB-D 标定 + 点映射 + 三维恢复”。但现在回头看,我觉得它真正有价值的地方不在功能罗列,而在于它体现了一种后来我反复使用的方法:
当现成 API 的问题定义与任务本体并不一致时,继续围绕 API 修补往往不是正路。更重要的是回到几何本身,把问题改写成更贴合任务的结构。
这套方案就是一个很具体的例子。它不是继续沿着厂商提供的整幅 RGB–Depth 稠密映射接口往前堆,而是把问题重写成了一个面向少量关键点的稀疏几何查询问题。
1. 任务本体到底是什么
在 RGB-D 项目里,一个最自然的说法是:“需要 RGB 图和深度图对齐。”
但这个说法虽然常见,却不一定准确。
对于很多工业场景,真正关心的往往不是“整幅 RGB 图和整幅 D 图都精确稠密对应”,而是下面这类更具体的问题:
- RGB 图上的某几个关键点,在深度图上到底对应哪里;
- 这些点的三维坐标能否稳定恢复;
- 后续能否与 IR、双目或其他几何线索融合,得到更稳的三维参数。
也就是说,任务本体其实更接近:
给定 RGB 图上的少量关键点,快速而稳定地找到其在深度图中的对应位置,并恢复其三维坐标。
这个表述看似只是措辞变化,实际上已经决定了算法路线。
如果问题是“整幅图稠密映射”,那么自然会去找 full-frame remapping。
如果问题是“少量点的快速恢复”,那么更自然的路线其实是稀疏、几何化、按需求值。
2. 为什么没有直接采用厂商 API
当时 PICO Zense 已经提供了 RGB 与深度图之间的映射 API。直观地说,它的做法更像是先把深度图“抬回三维空间”,再从三维空间重新投影到 RGB 相机的像平面;如果还需要从 RGB 反查到深度图,则再沿这条链条反向建立对应。这样的路线很自然,也很通用,但它对应的其实是整幅图像之间的全局几何重投影,而不是少量关键点的按需查询。
下面这张图来自当时保留下来的设计文档:

图 1:RGB 映射到深度图的效果对比。左上为厂商 API 映射效果,左下为当时原型算法的映射效果,右上为 RGB 图,右下为深度图。深度缺失与边界不稳定会直接影响通用 API 的映射质量。
如果目标真的是“整幅 RGB–Depth 稠密对齐”,这种 API 是自然的。
但对这里的任务来说,它至少有三个问题:
- 它解决的是整幅图的通用稠密映射,不是少量关键点的稀疏查询。
- 它的质量高度依赖深度图本身的稳定性,而深度图在真实场景中经常存在边界跳变、孔洞和信息丢失。
- 为了得到几个点的对应关系,先计算整幅图映射场,属于明显的过度计算。
因此,这里的关键判断其实不是“API 好不好”,而是:
API 解决的不是这个任务真正要解决的问题。
这件事后来给我留下了很深的印象。很多系统级问题,并不是缺少工具,而是工具的抽象层级与任务的抽象层级并不一致。
3. 几何模型:RGB、D、IR 不是三张图,而是一条几何链
这套方案的基础并不神秘,本质上仍然是一个标准的多传感器相机模型:
- RGB 相机有自己的内参与畸变;
- D 相机也有自己的内参与畸变;
- RGB 与 D 之间存在相对位姿;
- IR 与 D 在设备内部通常具有更紧的几何关联;
- 如果 IR 更适合标定,那么完全可以走 RGB–IR 这条更稳的链,再间接约束 D。
原始文档中的几何示意图如下:
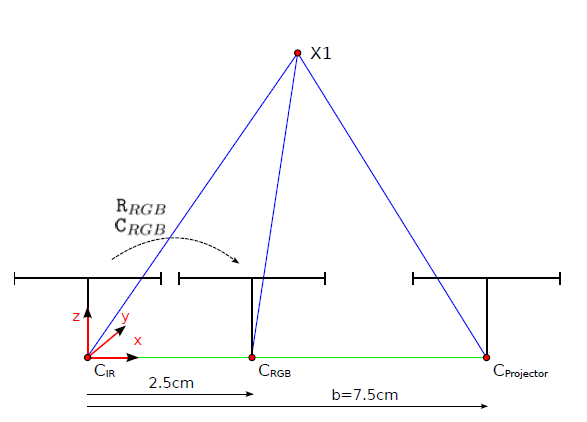
图 2:RGB-D 相机的几何模型示意。RGB、D 与 IR 不是孤立输出,而是共同处在一条跨传感器几何链中。
3.1 针孔模型
对于 RGB 相机,采用标准针孔模型:
\[\lambda \begin{bmatrix} u \\ v \\ 1 \end{bmatrix} = K \begin{bmatrix} R & t \end{bmatrix} \begin{bmatrix} X \\ Y \\ Z \\ 1 \end{bmatrix},\]其中内参矩阵为
\[K= \begin{bmatrix} f_x & s & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \end{bmatrix}.\]从实现角度看,这只意味着需要维护内参与逆内参,并在投影、反投影时调用稳定的基础线性代数操作。真正重要的并不是具体代码形式,而是:像点与三维点之间的关系始终通过一条明确的相机模型链来处理。
3.2 径向畸变
原型里采用的是一个简化的径向畸变模型。若归一化像平面点为 $(x,y)$,则定义
\[r^2=x^2+y^2,\]并令
\[\delta(r)=k_1 r^2 + k_2 r^4 + k_3 r^6.\]于是理想到实际像点的映射可写成
\[\begin{aligned} u &= u_0 + (u_0-c_x)\,\delta(r), \\ v &= v_0 + (v_0-c_y)\,\delta(r), \end{aligned}\]其中 $(u_0,v_0)$ 是不带畸变的像点。
这里并没有追求最复杂的反畸变实现,而是采用了一种足够直接、足够可控的径向模型。它未必是最“豪华”的做法,但足以说明整套方法是在沿真实几何链条求值,而不是依赖二维经验映射去硬凑跨传感器对应。
3.3 RGB 到 D 的刚体关系
设 RGB 相机坐标系中的点为 $p_{rgb}$,D 相机坐标系中的对应点为 $p_d$,则有
\[p_d = R_{d\leftarrow rgb} \, p_{rgb} + t_{d\leftarrow rgb}.\]所以一旦跨传感器几何关系被标定出来,所谓“RGB 点映到深度图”其实就不再是图像搬运,而是:
把 RGB 像点放回三维,再通过跨传感器坐标变换投到 D 相机。
这一步看起来普通,但它决定了后面整条链条的风格:
问题的主场不再是二维像素平面,而是三维几何关系本身。
4. 标定链条:为什么除了 RGB–D,还要认真考虑 RGB–IR
当时方案里并不是只设计了一条路径,而是留了几种层次不同的做法。
4.1 RGB–D 联合标定
最直接的思路,是用棋盘格、平面模型和对应点,拟合:
- RGB 相机内参;
- D 相机内参;
- RGB 与 D 的相对位姿。
对应的初始化与细优化示意如下:
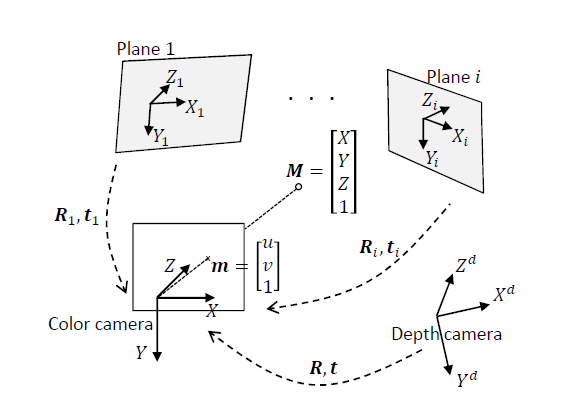
图 3:RGB–D 联合标定的初始化示意。重点不是一开始追求极致精度,而是先建立一个足够可靠的几何起点。

图 4:平面模型与标定场景示意。对于深度相机而言,平面通常比边界跳变强烈的对象更适合作为几何参照。
这里有一个很现实的判断:深度图并不天然适合直接作为高精度棋盘格角点检测的入口。
它会有孔洞、跳变和不稳定区域,所以如果直接在 Depth 图上强行做角点级初始化,往往很吃力。
因此在设计文档里,平面模型被放在了较优先的位置。原因并不复杂:
- 平面是最简单的流形参照;
- 深度图对平面通常比对边界跳变更稳定;
- 平面也更适合后续做几何残差和全局一致性约束。
4.2 RGB–IR 双目标定
现在回头看,这套方案里更成熟的一笔,其实是不执着于“必须直接搞定 RGB–D”。
因为 IR 图像在很多设备上,比 Depth 图更自然地呈现棋盘格角点。
于是如果 IR 与 D 在几何上天然绑定,那么就完全可以转而走 RGB–IR 双目标定,再间接约束 D。
相关图示如下:

图 5:IR 图像中的棋盘格示意。对于这类设备,IR 常常比深度图更适合作为标定入口。

图 6:IR 图与 RGB 图中的标定板示意。把 RGB–IR 视作更稳的双目标定路径,很多时候比直接在深度图上强行找角点更自然。
这件事本身也很能说明问题:
在底层视觉系统里,好的方案不一定是“最直观”的链条,而是“最稳定的几何中介”。
5. 核心转折:把“映射问题”改写成“几何查询问题”
如果这套方案只有标定,它还只是一个标准 3D 视觉模块。它真正值得写下来的地方,是在线映射部分。
5.1 问题的重新表述
厂商 API 想做的是:
建立整幅 RGB 与 D 之间的通用稠密对应关系。
而这里真正需要解决的是:
给定 RGB 上一个关键点,快速找到它在 D 图上的对应位置以及三维坐标。
于是在线阶段的任务不再是“生成一张映射场”,而是:
- 从一个 RGB 像点出发,生成一条 3D 视线;
- 在工作深度范围内沿这条视线产生候选三维点;
- 把每个候选点投到 D 相机;
- 检查深度图是否支持这个几何假设;
- 一旦支持,就返回对应位置与三维坐标。
这已经不是 remapping,而更像一个 task-specific sparse geometric query。
5.2 反投影:从像点到射线
给定 RGB 像点
\[p_{rgb} = (u,v,1)^\top,\]先做反畸变,再乘逆内参,得到归一化像平面方向:
\[\tilde p_{rgb}=K_{rgb}^{-1} p_{rgb}^{(undist)}.\]于是 RGB 相机中的视线可写成
\[\ell(s)=o_{rgb}+\alpha(s)\,n_{rgb},\]其中 $o_{rgb}$ 为 RGB 光心,$n_{rgb}$ 为视线方向。
在线阶段并不在二维图像中搜索对应点,而是只在预设的工作深度区间内,沿这条视线生成候选三维点。于是原本可能看起来像“跨图搜索”的问题,被压缩成了一条三维视线上的一维搜索。
这一步非常关键。算法并不尝试为整幅图像建立 RGB–Depth 的稠密对应场,而只是围绕单个关键点构造一组有明确几何意义的候选假设。这样一来,搜索空间从整幅图像甚至整个三维空间,下降为受限深度区间内的单参数搜索。
5.3 将候选点投影到 D 相机
对每个候选点 $X(s)$,先通过刚体变换送到 D 相机坐标系:
\[X_d(s)=R_{d\leftarrow rgb} X(s)+t_{d\leftarrow rgb}.\]然后利用 D 相机的投影模型,将其投到深度图像平面,得到候选像素:
\[p_d(s)=\Pi_d(X_d(s)).\]这里的 $\Pi_d$ 包含 D 相机的内参以及畸变模型,因此它不是一个简单的二维仿射变换,而是一条完整的针孔投影链。于是,每个三维候选点都会在深度图上对应到一个候选像素位置。
从几何意义上看,这一步表达得很直接:
每个 RGB 候选点都被重新投成 D 相机中的一个像素假设。
5.4 深度一致性验证
设候选点到 D 光心的预测距离为
\[d_{\mathrm{pred}}(s)=\|X_d(s)-o_d\|,\]深度图在对应像素处读出的实测深度为
\[d_{\mathrm{obs}}(p_d(s)).\]则可构造一个非常直接的几何一致性残差:
\[\varepsilon(s)=d_{\mathrm{pred}}(s)-\bigl(a\,d_{\mathrm{obs}}(p_d(s))+b\bigr),\]其中 $a,b$ 用于补偿深度尺度与偏置误差。
若
\[0<\varepsilon(s)<\tau,\]则认为这个候选点与深度观测一致,并直接返回。
整个在线过程可以概括为:
Input: RGB feature point p, depth interval [z_near, z_far]
Output: corresponding depth pixel and recovered 3D point
1. Undistort and back-project p into a viewing ray in the RGB camera.
2. For each sampled depth value s in [z_near, z_far]:
a. Generate a 3D candidate point X(s) on the ray.
b. Transform X(s) into the depth camera frame.
c. Project X(s) onto the depth image to obtain p_d(s).
d. Read the observed depth at p_d(s).
e. Evaluate the depth-consistency residual.
f. If the residual is within threshold, accept and return.
3. If no candidate is accepted, return failure.
因此,这一过程真正做的并不是“先重建整张 3D 场景,再去找点”,而是:
给定一个 RGB 点,在一条视线上连续提出 3D 假设,并让深度图来验证哪个假设成立。
这是一种很典型的 hypothesis generation + sensor validation 结构。
6. 为什么它会比整图 API 快很多
现在回头看,这个速度优势其实并不神秘,关键有四条。
6.1 稠密问题变成了稀疏问题
厂商 API 解决的是 full-frame dense mapping;
这里解决的是 one-point sparse query。
两者复杂度层级本来就不同。
6.2 搜索空间被压缩成一维
不是在整张深度图上找,不是在整个 3D 空间里暴力找,而是只在一条视线的深度区间内采样。
若采样步长为 $\Delta z$,则在线搜索复杂度近似为:
这比 full-frame remapping 的代价轻得多。
6.3 每个样本只做常数级计算
每一步只包含:
- 若干
3×3线性变换; - 一次投影;
- 一次深度读取;
- 一次残差比较。
没有整幅重采样,没有稠密映射缓存,也没有整图回拉。
6.4 有早停
只要遇到第一个几何一致的候选点就直接返回,因此平均代价往往低于最坏代价。
所以这套方法快,不是因为某种神奇的底层技巧,而是因为:
问题被改写成了一个更低维、更受约束、与任务真正一致的几何求值过程。
7. 工程边界:它是一个原型,而不是被精修过的展示品
既然这是一篇技术博客,有些边界也应当明说。
7.1 它是原型代码,不是整理后的展示代码
这套原型当时做得很快,后来也没有继续展开,因此实现明显带有工程原型痕迹,而不是为发表或展示精修过的版本。
例如:
- 有些资源释放并不完整;
- 某些参数和阈值是非常直接的工程设置;
first-hit的返回策略强调“快速可用”,不是全局最优;- 某些基础函数从今天看可以写得更规整。
7.2 关于深度数据类型的一处疑点
从今天回看,这个原型里有一处值得特别小心的地方:
如果深度图确实按 CV_16UC1 保存原始深度,那么任何将其读入 8 位变量的写法都会导致精度截断。对于依赖深度一致性残差的在线判定来说,这类细节是不能忽略的。
我现在已经无法完全确认这是某个阶段版本差异、整理过程中的笔误,还是当时在线分支里对深度做过另外的缩放处理。
但把这一点明确写出来反而更好,因为它说明:这里整理的目标不是把一个原型包装成完美作品,而是把一条真正有价值的几何路线说清楚。
8. 这件事后来留下的真正启发
现在回头看,这个项目真正重要的,不是“做出了一个比 API 更快的 RGB–D 点映射原型”,而是它再次证明了一件后来越来越明确的事:
很多视觉问题的关键,不在于有没有现成工具,而在于是否抓住了问题真正的几何形态。
如果问题本来是一个“关键点稀疏映射与三维恢复”问题,那么沿着整图稠密 API 修修补补,永远不如把它重新写成一条视线上的几何一致性查询来得自然。
这也是为什么后来我越来越倾向于从结构、几何和表示空间出发去组织问题,而不是停留在位图层和接口层面。
从这个意义上说,这个原型虽然短、虽然没有继续展开,却已经很清楚地露出了后来很多工作的同一条方法论线索:
- 先找一个更合适的几何中介;
- 把问题压到更低维、更可控的表示里;
- 再在那个结构里做求值、拟合或优化。
9. 结尾:如果不把这类工作写下来,它就真的会散掉
这套 RGB-D 标定与稀疏三维查询方案,当年没有写成论文,也没有被整理成一篇正式的技术文档。现在还能留下来的,主要只是内部设计说明、部分代码和我自己的回忆。
但我仍然觉得它值得写下来。
因为它代表的不是某一个小功能,而是一种很典型的底层视觉判断力:
- 不迷信厂商 API;
- 先把跨传感器几何关系讲清楚;
- 先选对几何参照物;
- 再把在线问题压缩成真正贴合任务的形式。
如果要把这篇文章压缩成一句话,我更愿意这样说:
这不是一个“RGB-D 标定模块”的回顾,而是一条从几何建模出发,把跨传感器点对应问题改写成任务导向稀疏查询问题的底层视觉路线。
对我来说,这类东西的价值并不在于它当年有没有继续做大,而在于:它很早就证明了一件事——只要问题写对了,很多看似笨重的视觉流程,其实可以变得非常直接。
作者: 冯玮(Wei Feng)
邮箱: weifeng@stu.ouc.edu.cn