English Abstract
This article explains why the curved-surface pattern inspection system should not be hard-wired into a single fixed detection chain. While the main pipeline is well suited to structured objects such as characters and regular patterns, many real production targets—such as QR codes, barcodes, rule-based logos, glue residue, and lint—do not fit naturally into the same template–registration–measurement framework. To keep the main chain stable and clean, the system introduces a plugin mechanism that routes heterogeneous objects into dedicated local analysis paths through XML and block-level configuration. This mechanism supports both rule-based plugins and AI modules, allowing the system to evolve from a fixed algorithm set into an extensible inspection platform.
在前面几篇里,我已经把这套系统的主检测链讲得比较清楚了:模板如何组织,xml 如何承接结构对象,两层配准如何把模板带入实测图像,缺陷如何沿测量集被逐点测出来,以及整套系统为什么能够在真实产线上稳定跑起来。
但即便到了这一步,仍然有一个问题没有回答:
这套系统是不是只能处理那类已经被模板、骨架、block、注册集和测量集组织好的标准对象?
真实现场里,答案显然是否定的。
因为产线对象并不总是规则地落在主检测链最擅长处理的那一类结构上。条码、二维码、某些规则 logo,甚至残胶、毛絮这类弱结构或纹理型异常,都不一定适合被强行塞进原有那条“模板—配准—测量”的主链之中。它们有的在几何组织上和字符 / pattern 完全不同,有的在检测逻辑上更像解码或分类问题,有的则更适合交给深度模型做局部复核。
这也就意味着:如果继续把所有对象都硬写进主 DLL,系统会越来越臃肿,越来越充满特例,最后既损伤主链的清晰性,也损伤整个系统的可维护性。
所以,这套系统必须再长出一层能力:
当某类对象不适合继续纳入主检测链时,系统要能把它以插件的方式接进来。
也正是在这一层上,这套系统开始从“固定算法集合”转向“可扩展检测平台”。
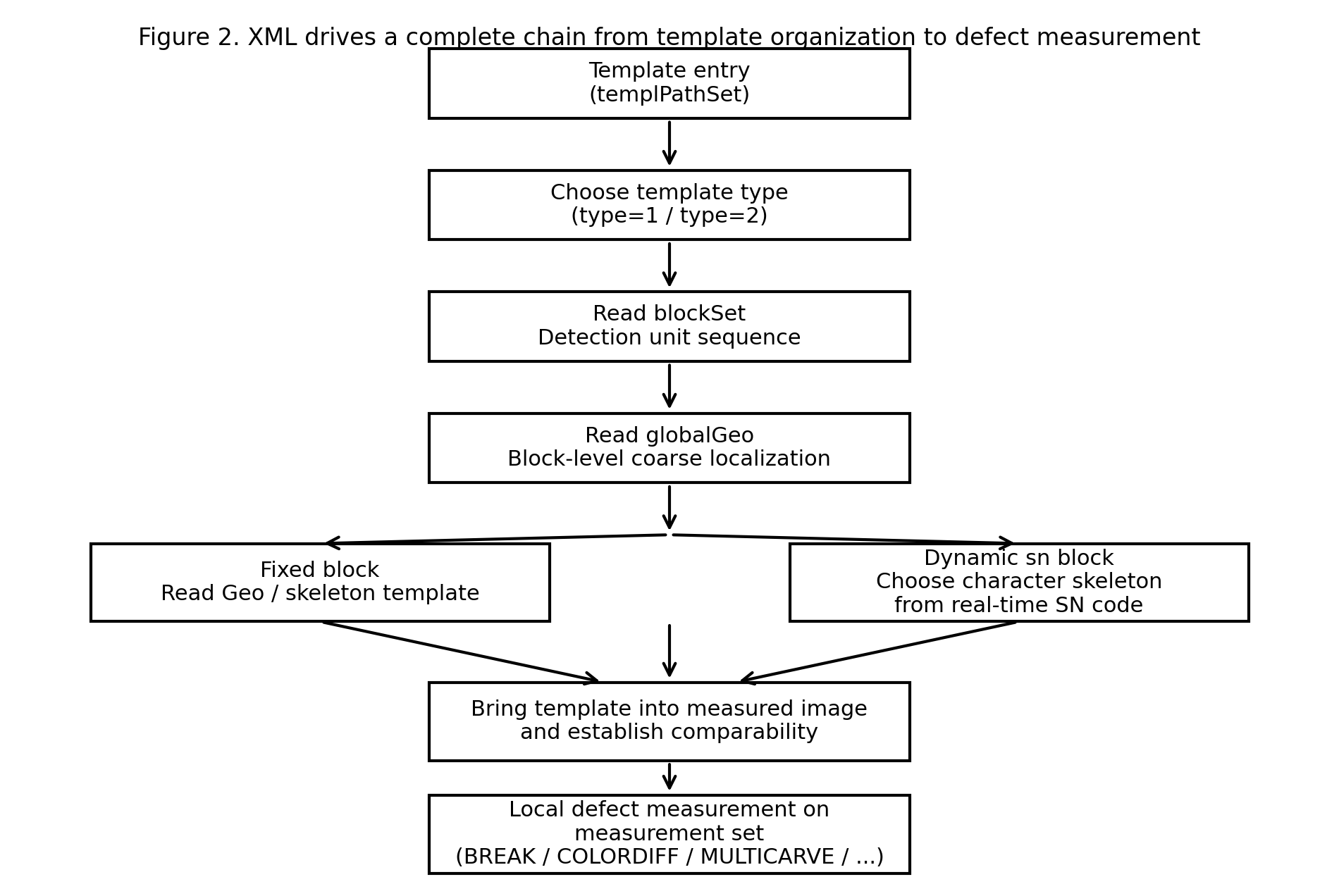
如果把这套系统已经形成的主链、插件链和 AI 复核链压缩成一张总图,它大致可以表示为下面这样:
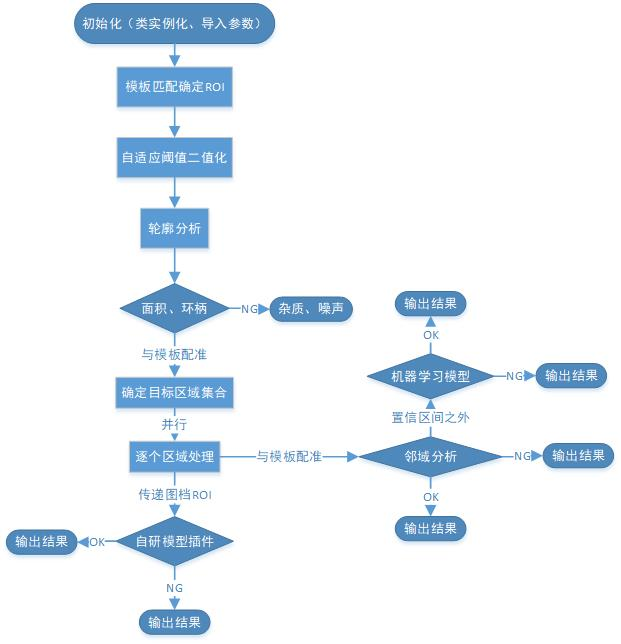
图 1:系统整体流程图。从初始化、轮廓分析、并行配准,到主检测链上的局部测量,再到对可疑邻域引入深度神经网络二次分类,以及对不规则特殊对象走插件路径,这些环节共同构成了系统的完整运行链。
这一篇,我想专门把这层能力讲清楚:
- 为什么主检测链不该承包一切;
- 插件接口到底在统一什么;
- XML 和 block 配置是怎么把插件正式接进系统的;
- 为什么二维码、条码和规则 logo 特别适合走插件;
- 为什么插件不仅能接住特殊规则对象,也能接住 AI 模块;
- 为什么这一层真正改变的,不只是功能多少,而是系统的性质。
一、为什么这套系统需要插件,而不是继续往 DLL 里加分支
一个固定检测系统最容易走向的方向,就是每遇到一个新对象,就往核心代码里再加一个特例分支。开始时这样做看起来很方便,因为功能都还在同一个 DLL 里,调试路径也看似集中。
但这条路走不远。
因为前面几篇已经说明,这套系统的主检测链其实是围绕一类“可被结构化组织”的对象建立起来的:它们能够进入模板层,能够被 block 切分,能够在 xml 中形成骨架或特征点集合,能够进一步进入配准和测量链。这条主链之所以成立,是因为它处理的是结构化 Pattern 对象。
而一旦把完全不同性质的对象继续往里硬塞,主链就会开始变脏。主系统原本清楚的模板逻辑、配准逻辑和测量逻辑,会被越来越多的特例分支污染;配置会开始混乱;维护和验证的成本也会迅速上升。
所以,插件机制的意义不是“让系统显得高级一点”,而是:
把那些不适合继续纳入主链的特殊对象,从核心检测链里剥离出来。
换句话说,主系统负责提供统一运行框架,插件负责承接不适合纳入主链的异构检测对象。
二、插件接口到底在统一什么
如果说插件的意义是把异构对象从主链中剥离出来,那么接下来最关键的问题就是:这些完全不同的对象,最后为什么还能被统一接入同一套系统?
答案就在插件接口。
从系统边界上看,插件接收的是当前 block 的局部 ROI 图像、尺寸信息、检测类型、附加业务输入以及结果输出容器;插件执行完成后,再把缺陷结果以统一格式返回给主系统。也就是说,插件虽然内部算法可以完全不同,但在系统边界上,它必须满足统一输入输出协议。
它最核心的作用,并不是让主系统知道“插件内部具体怎么做”,而是让主系统知道:
- 当前拿到的是哪个 ROI;
- 需要执行哪种检测任务;
- 有没有附加业务输入,例如 SN code;
- 返回的缺陷集合是什么;
- 最终结果是 OK、NG 还是其他状态。
也就是说,插件并不接管整套系统,它只接管:
当前 ROI 上那一段不适合由主链继续完成的局部检测任务。
这一点在接口设计上体现得很清楚。插件的增强版接口大致如下:
/*!
measure defects for character or pattern
\param mat_roi bitmap of measurement area
\param rows
\param cols
\param code input sn code
\param detectType
\param res_set the result set
\param e_num the size of the result set
\return the result:1:OK;0:NG or other
*/
typedef int(*Pattern_analysis)(
unsigned char *mat_roi,
int rows,
int cols,
const char *code,
int detectType,
int(*res_set)[5],
int &e_num);
这里还有一个值得说明的细节:插件接口本身也不是一开始就完全固定不变的。早期接口更多服务于纯图像型对象,而在后续演进中,为了支持 SN code、条码、二维码等依赖附加业务输入的对象,接口进一步引入了 code 参数。也就是说,这套插件机制本身也经历了从“纯图像型插件”向“图像 + 业务输入型插件”的扩展。
与此同时,detectType 也并不只是一个简单开关,而是直接沿用了系统原有的缺陷语义集合,例如:
1:镭断2:色异常4:偏移8:多雕16:码数量异常32:无码64:镭错128:SN 码数量异常256:杂质
这意味着插件虽然内部算法不同,但它的输出并不是“另起一套语义”,而是继续回到系统统一的缺陷表达里。
三、XML 和 block 配置是怎么把插件正式接进系统的
插件之所以真正成为系统能力,不只是因为代码里可以 LoadLibrary,而是因为它已经被正式接进了配置链。
也就是说,插件不是一个游离在系统之外的外挂,而是会通过 XML 与 block 配置进入主系统的运行框架。某个对象一旦被配置为插件检测路径,它就不再走标准的主检测链,而是被路由到对应的插件模块中去完成局部分析。
这一点非常关键。因为它说明这套系统并不是简单地“支持动态库”,而是已经在配置层面承认了插件的存在:模板主链继续负责标准结构化对象,而插件链则作为正式分支,承接那些不适合硬塞进主链的特殊对象。
从系统组织角度看,这种分工主要体现在两部分。
第一部分,是 XML 中对插件信息本身的配置。
第二部分,是 block 标签中通过 methods="1" 等方式,把当前 block 路由到插件检测路径。
所以,插件机制之所以成立,不只是因为 DLL 能动态加载,而是因为它已经进入了 XML 与 block 的配置组织层。换句话说,主系统不是在运行到一半时“临时想起还有个插件可调”,而是在模板、block 和检测路径这一层就已经明确:哪些对象继续走主检测链,哪些对象应当转交给插件去处理。
如果借用软件架构中的语言来描述,这一层更接近一种“工厂式装配 + 策略式调用”的插件化边界。主系统并不在编译期写死二维码、条码、规则 logo 或 AI 模块的具体实现,而是先根据配置在运行时装配对应插件,再通过统一分析入口把它们作为当前 ROI 上的局部检测策略接回系统。对主系统来说,被统一起来的并不是各类对象内部到底采用了什么算法,而是它们在系统边界上的输入输出协议。
这也正是插件机制真正有价值的地方。它不是把所有特殊对象重新塞回主链,而是在主系统和对象特定算法之间建立起一条清楚的边界:主系统负责统一装配、统一调度和统一结果回收,而二维码、条码、规则 logo、AI 模块等对象,则各自通过统一入口接入当前 ROI 的局部检测任务。
插件管理相关代码也很直观。下面这段代码的关键不在于 Windows API 本身,而在于它明确了:主系统按统一方式加载插件,插件再通过统一函数入口回到系统中。
class PlugIn
{
public:
PlugIn()
{
hDll = NULL;
}
virtual ~PlugIn()
{
if (NULL != hDll)
{
FreeLibrary(hDll);
}
}
bool Load(Param4PlugIn *param)
{
wchar_t w_path[100];
swprintf(w_path, 100, L"%hs", param->path);
hDll = LoadLibrary(w_path);
if (NULL == hDll)
{
return false;
}
else
{
strcpy(name, param->name);
analysis = (Pattern_analysis)GetProcAddress(hDll, "pattern_analysis");
return true;
}
}
Pattern_analysis analysis;
private:
HINSTANCE hDll;
char name[MAX_PATH];
};
这段代码表面上只是 DLL 加载,但从系统边界看,它真正完成的是两件事。
第一,它把“插件如何被找到、被装配、被注册”统一了起来。主系统不需要在主链代码里到处写特例判断,而是通过统一装配入口,把对象特定算法接入当前运行框架。
第二,它把“插件内部算法是什么”和“主系统如何使用插件”清楚地分开了。对主系统来说,二维码插件、条码插件、规则 logo 插件,甚至后面的 AI 插件,最终都只是统一边界上的一个 analysis 入口。被统一起来的不是算法内部细节,而是系统边界上的输入输出协议。
所以,这一层最值得强调的,并不是 Windows API,也不是“动态加载”这几个字本身,而是:
插件机制通过统一配置、统一装配和统一调用,把主系统框架和对象特定算法清楚地分开了。
也正因为如此,插件才不是一个附着在系统外部的小技巧,而是真正进入了这套曲面 Pattern 检测系统内部结构的一层平台化边界。
四、为什么二维码、条码和规则 logo 特别适合走插件
这一层最典型的例子,就是二维码。
二维码并不是“再加一种 pattern”这么简单。它会直接打破原有 block 的几何格局。对标准字符或规则 pattern 来说,系统可以先通过 block 把局部结构组织起来,再在 block 内做模板、配准和测量;但二维码的几何组织方式与这一套主链并不匹配。它既不是简单字符,也不是那类能够自然被骨架、注册集和测量集组织起来的标准局部对象。
如果硬要把二维码写进原有 block 主链,不只是代码不优雅,更重要的是会破坏原有体系的稳定性。也正因为如此,二维码最适合作为插件来处理。它不必强行服从原有 block 的几何组织逻辑,而可以走自己的检测与解码路径。
这不是抽象推理,而是实际发生过的需求:二维码确实出现在索尼游戏手柄的镭雕图案中,而且还专门形成过针对二维码缺陷检测的专利。也就是说,二维码并不是理论上的“也许会遇到”,而是真实出现过、并且已经证明不适合硬塞进主检测链的对象。
条码与某些规则 logo 的情况也是类似的。条码和二维码都更适合独立检测与解码;而一些规则 logo 虽然未必需要复杂解码,但也不一定非要走骨架配准主链,很多时候用灰度模板匹配等更轻量的方式就足够。
这时再看这套系统的整体结构,主链与插件链之间的分工就会更清楚:
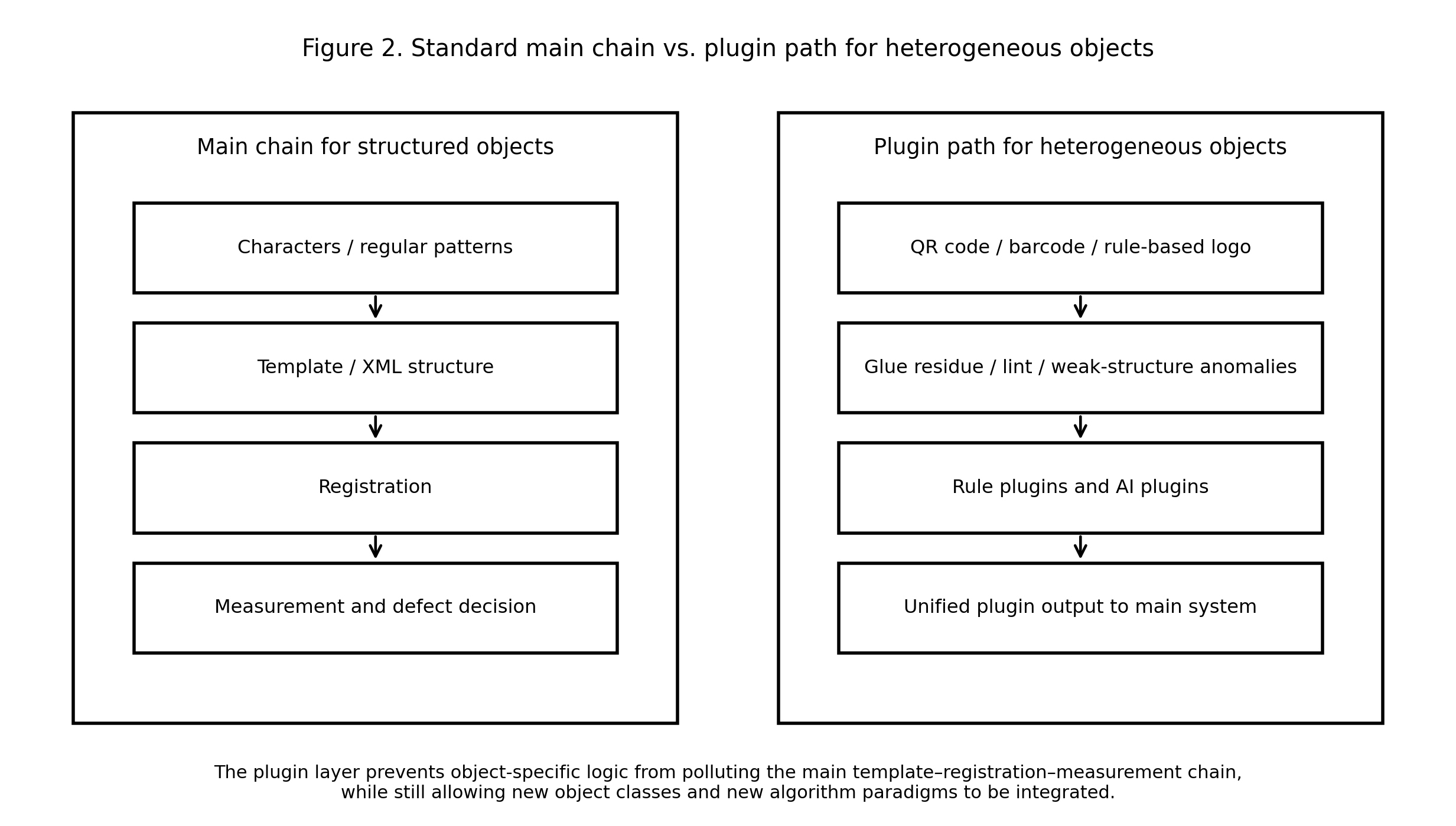
图 2: 主检测链与插件路径的对照示意图。左侧是面向标准结构化对象的模板—配准—测量主链,右侧是面向二维码、条码、规则 logo 以及残胶、毛絮等异构对象的插件路径。插件的价值,不在于“多一种功能”,而在于避免用特例污染主链。
所以,插件在这里的意义非常明确:它不是只为“高难对象”服务,而是为所有与主检测链组织方式不匹配的对象提供统一接入方式。
五、插件管理器真正体现的,不是动态库,而是平台边界
如果只从代码层面看,插件管理器做的事情似乎并不复杂:加载 DLL、获取函数地址、保存插件指针、按索引取回插件实例。
但这件事真正重要的地方,并不在于 Windows API 本身,而在于它明确划出了一条系统边界:
- 主系统知道如何加载插件;
- 插件知道如何按统一接口返回结果;
- 主系统不需要知道插件内部到底是模板匹配、解码算法、规则算法,还是别的东西。
换句话说,插件管理器真正做的,不是“动态加载”这个动作,而是:
把系统框架和对象特定算法清楚地分开。
这意味着,主系统可以继续保持自己的主干清晰,而不同对象的特定检测逻辑,则被隔离在各自插件内部。真正被统一起来的,不是算法内部细节,而是系统边界上的输入输出协议。
六、为什么插件不仅能接住特殊规则对象,也能接住 AI 模块
插件机制如果只能接规则型特殊对象,它还只是“扩展几个功能”;但一旦它连 AI 模块都能接住,系统的性质就变了。
这套系统里,AI 模块并不是主链的一部分,而是以插件形式接入,用来检测残胶和毛絮这类对象。这个设计本身就说明了一件事:系统并没有把深度学习写死进主检测链,而是把它放在一个更合适的位置上。
这背后的原因其实很清楚。
残胶、毛絮这类对象,并不像字符或规则 pattern 那样容易被模板、骨架、注册集和测量集稳定刻画。它们更像是局部杂质、弱结构异常或纹理型异常。如果把这类对象硬塞进主链,不仅会让主链变脏,而且效果也未必稳。更合理的方式,是让主链继续负责结构化对象,而让 AI 插件去承接这类弱结构、杂质型或纹理型对象。
更重要的是,这里的 AI 也不是“扫整张图”的主干模型,而更像一个二级判别器。算法会先把置信区间之外的可疑点邻域位图截取出来,再由深度模型对这些局部邻域进行分类。也就是说,AI 并不是替代主链,而是在主链筛出可疑对象之后,对这些局部区域做进一步复核。
如果把这一层再压缩成一条工程链,AI 插件在系统中的位置大致如下:
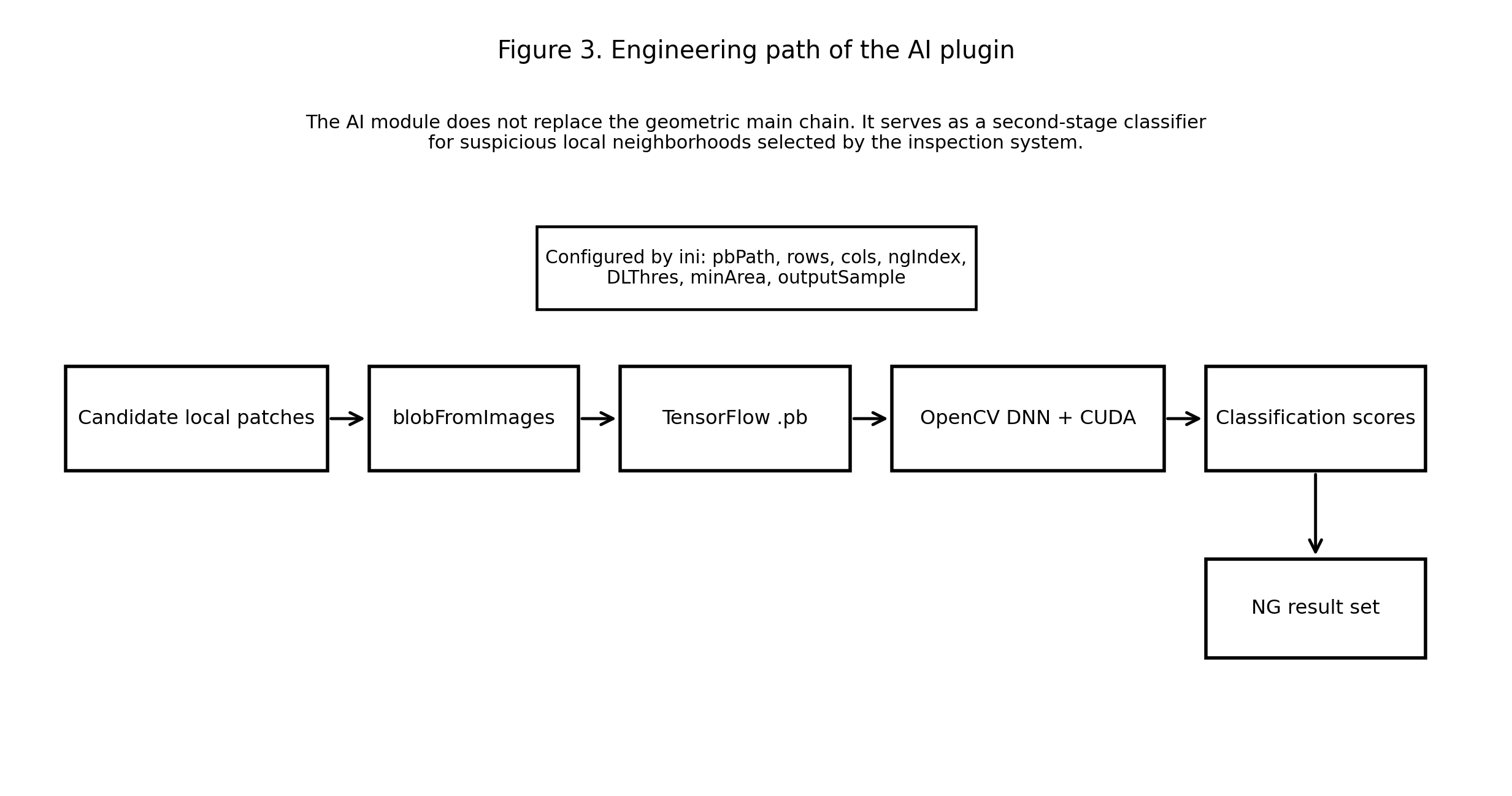
图 3: AI 插件的工程接入路径。主检测链先筛出可疑局部邻域,再把这些局部样本转为批量输入,加载 .pb 模型并通过 OpenCV DNN 与 CUDA 完成推理,最后将分类结果回写为统一缺陷输出。
从工程上看,这个模块也已经很完整:
- 训练框架可以来自 TensorFlow、PyTorch、Caffe、Keras;
- 模型最终导出为
*.pb文件; - 运行时由
ini配置加载模型路径、输入尺寸、输出维度、阈值等参数; - 推理阶段通过 OpenCV DNN 调用 TensorFlow 模型,并使用 CUDA 加速。
这一点从代码里看得很清楚,例如模型加载和 CUDA 后端:
bool NeuralNetwork::initial_tf_model(string path)
{
if (6 > path.length())
{
return false;
}
net = readNetFromTensorflow(path);
net.setPreferableBackend(DNN_BACKEND_CUDA);
net.setPreferableTarget(DNN_TARGET_CUDA);
if (net.empty())
{
Logger::Instance()->TraceError("dnn:no model");
}
else
{
Logger::Instance()->TraceError("Deep network model has loaded successfully...");
}
return true;
}
以及批量局部样本的输入与前向推理:
void NeuralNetwork::tf_inv_net_defect(vector<double> result_set, vector<Mat> &matset4dl)
{
int size = matset4dl.size();
if (!isvalid || 0 == size)
{
return;
}
Mat inputBlob = blobFromImages(matset4dl, 1.0 / 255, Size(cols, rows), Scalar(), false, false);
net.setInput(inputBlob);
Mat pred = net.forward();
for (int i = 0; i != size; ++i)
{
float *v = pred.ptr<float>(i);
softmax(v);
result_set.push_back(v[ngIndex]);
}
}
所以,这一层最值得强调的,不是“用了 AI”,而是:
AI 也被纳入了同一套插件化接入机制。
七、所以,这一层让系统从“固定算法”变成“可扩展平台”
把前面的这些内容放在一起再看,就会发现:插件机制真正带来的,不只是几个额外功能,而是系统性质的变化。
如果没有插件,这套系统再强,也仍然更像一个“固定算法集合”:它有很强的主检测链,但新对象一来,就必须继续往 DLL 里加特例。
而有了插件之后,局面就不同了:
- 主链负责标准结构化检测对象;
- 规则插件负责条码、二维码、规则
logo等异构对象; AI插件负责残胶、毛絮等弱结构或纹理型异常;- 所有这些对象虽然内部算法不同,但都能通过统一边界接回主系统。
也正因为如此,这套系统才开始从“固定算法集合”长成“可扩展检测平台”。
所以,如果要把这一篇压缩成一句话,我更愿意这样说:
]]>插件机制真正改变的,不只是系统能多做几件事,而是它让这套曲面
Pattern检测系统从一组固定算法,长成了一个能够持续接入新对象、新算法范式和新业务需求的平台。